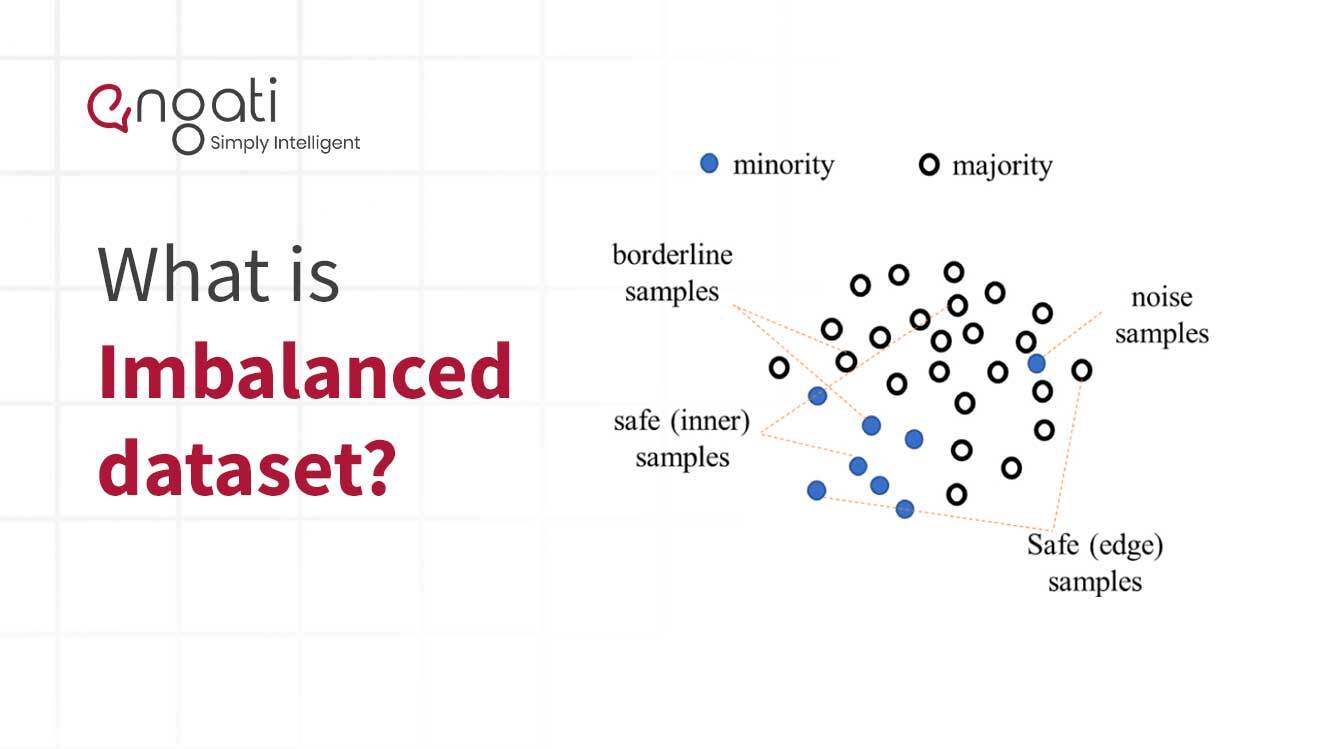
不均衡なデータは、2 つ以上のクラスの情報が等しく表現されていないタイプのデータです。このタイプのデータは、機械学習と予測分析の分野で一般的です。これは、あるクラスのデータ ポイントの量が他のすべてのクラスの量よりも大幅に多い場合に発生します。
不均衡なデータは、機械学習アルゴリズムにとって課題となる可能性があります。サンプル データに含まれる 1 つのクラスのデータ ポイントが多すぎるか少なすぎる場合、アルゴリズムはパターンを正しく検出できない可能性があります。その結果、アルゴリズムによる予測が不正確になる可能性があります。モデルがより正確であることを確認するには、すべてのクラスが同様の表現を持つようにデータのバランスをとる必要があります。
データのバランスをとるために、オーバーサンプリングやアンダーサンプリングなどのデータ サンプリング手法を使用できます。オーバーサンプリングでは、表現が少ないクラスからのより多くのデータ ポイントがサンプルに追加されます。一方、アンダーサンプリングは、より多くの表現を持つクラスからデータ ポイントを削除するプロセスです。データセットのバランスをとることで、機械学習アルゴリズムはより優れたモデルを作成し、より正確な予測を行うことができます。
不均衡なデータは、機械学習で使用されるデータセットに重大な影響を与える可能性があります。したがって、信頼性の高いモデルを作成し、正確な結果を得るために、使用されるデータセットのバランスが取れていることを確認するための措置を講じることが重要です。