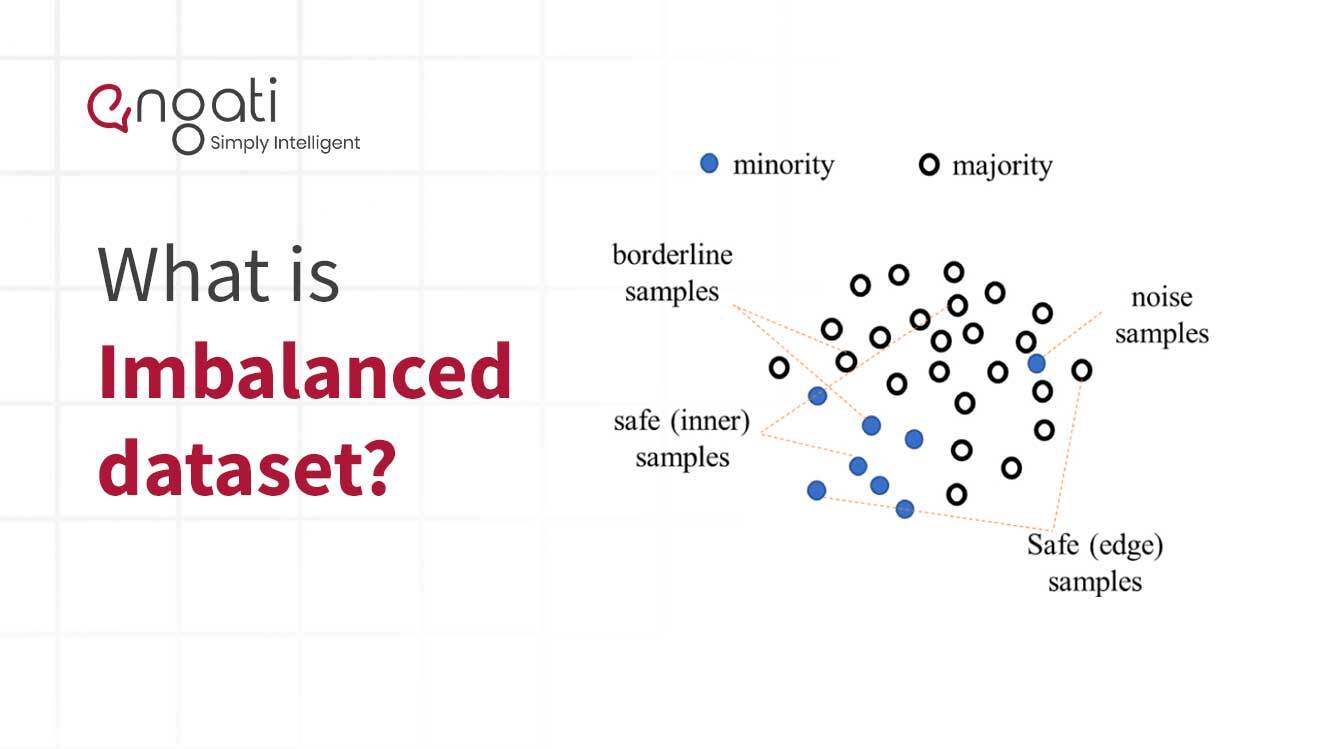
I dati sbilanciati sono un tipo di dati che hanno una rappresentazione ineguale di due o più classi di informazioni. Questo tipo di dati è comune nel campo dell’apprendimento automatico e dell’analisi predittiva. Si verifica quando la quantità di una classe di dati è significativamente superiore alla quantità di tutte le altre classi.
I dati sbilanciati possono rappresentare una sfida per gli algoritmi di apprendimento automatico. Quando i dati campione contengono troppi o troppo pochi punti dati di una classe, l'algoritmo potrebbe non essere in grado di rilevare correttamente i modelli. Di conseguenza, le previsioni fatte dall’algoritmo potrebbero essere imprecise. Per garantire che il modello sia più accurato, i dati devono essere bilanciati in modo da garantire che tutte le classi abbiano una rappresentazione simile.
Per bilanciare i dati, è possibile utilizzare tecniche di campionamento dei dati come il sovracampionamento e il sottocampionamento. Nel sovracampionamento, vengono aggiunti al campione più punti dati della classe con meno rappresentazione. D'altra parte, il sottocampionamento è il processo di rimozione dei punti dati dalla classe con maggiore rappresentazione. Bilanciando il set di dati, gli algoritmi di apprendimento automatico possono creare modelli migliori e fare previsioni più accurate.
I dati sbilanciati possono avere un profondo impatto sui set di dati utilizzati nell’apprendimento automatico. Pertanto, è importante adottare misure per garantire che i set di dati utilizzati siano bilanciati al fine di creare modelli affidabili e ottenere risultati accurati.