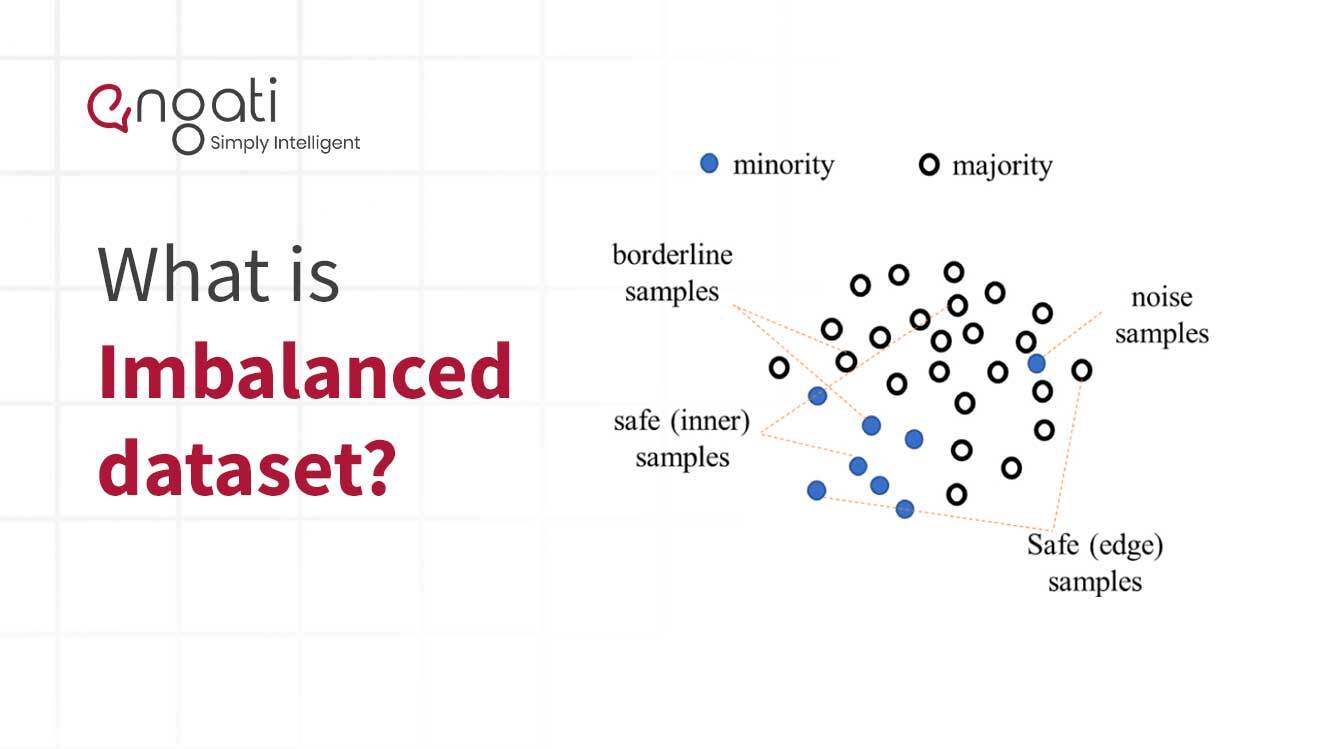
غیر متوازن ڈیٹا ڈیٹا کی ایک قسم ہے جس میں معلومات کی دو یا زیادہ کلاسوں کی غیر مساوی نمائندگی ہوتی ہے۔ اس قسم کا ڈیٹا مشین لرننگ اور پیشین گوئی کے تجزیات کے میدان میں عام ہے۔ یہ اس وقت ہوتا ہے جب ڈیٹا پوائنٹس کی ایک کلاس کی مقدار دیگر تمام کلاسوں کی مقدار سے نمایاں طور پر زیادہ ہوتی ہے۔
غیر متوازن ڈیٹا مشین لرننگ الگورتھم کے لیے ایک چیلنج ہو سکتا ہے۔ جب نمونے کے ڈیٹا میں ڈیٹا پوائنٹس کی ایک کلاس میں سے بہت زیادہ یا بہت کم ہوتے ہیں، تو الگورتھم پیٹرن کا صحیح طریقے سے پتہ لگانے کے قابل نہیں ہوسکتا ہے۔ نتیجے کے طور پر، الگورتھم کی طرف سے کی گئی پیشین گوئیاں غلط ہو سکتی ہیں۔ اس بات کو یقینی بنانے کے لیے کہ ماڈل زیادہ درست ہے، ڈیٹا کو متوازن ہونا چاہیے تاکہ اس بات کو یقینی بنایا جا سکے کہ تمام کلاسز کی نمائندگی یکساں ہے۔
ڈیٹا کو متوازن کرنے کے لیے، کوئی ڈیٹا سیمپلنگ کی تکنیکوں کا استعمال کر سکتا ہے جیسے اوور سیمپلنگ اور انڈر سیمپلنگ۔ اوور سیمپلنگ میں، کم نمائندگی کے ساتھ کلاس سے زیادہ ڈیٹا پوائنٹس نمونے میں شامل کیے جاتے ہیں۔ دوسری طرف، انڈر سیمپلنگ کلاس سے ڈیٹا پوائنٹس کو زیادہ نمائندگی کے ساتھ ہٹانے کا عمل ہے۔ ڈیٹا سیٹ کو متوازن کرکے، مشین لرننگ الگورتھم بہتر ماڈل بنا سکتے ہیں اور زیادہ درست پیشین گوئیاں کر سکتے ہیں۔
غیر متوازن ڈیٹا کا مشین لرننگ میں استعمال ہونے والے ڈیٹا سیٹس پر گہرا اثر پڑ سکتا ہے۔ اس طرح، یہ یقینی بنانے کے لیے اقدامات کرنا ضروری ہے کہ قابل اعتماد ماڈلز بنانے اور درست نتائج حاصل کرنے کے لیے استعمال کیے گئے ڈیٹا سیٹ متوازن ہوں۔