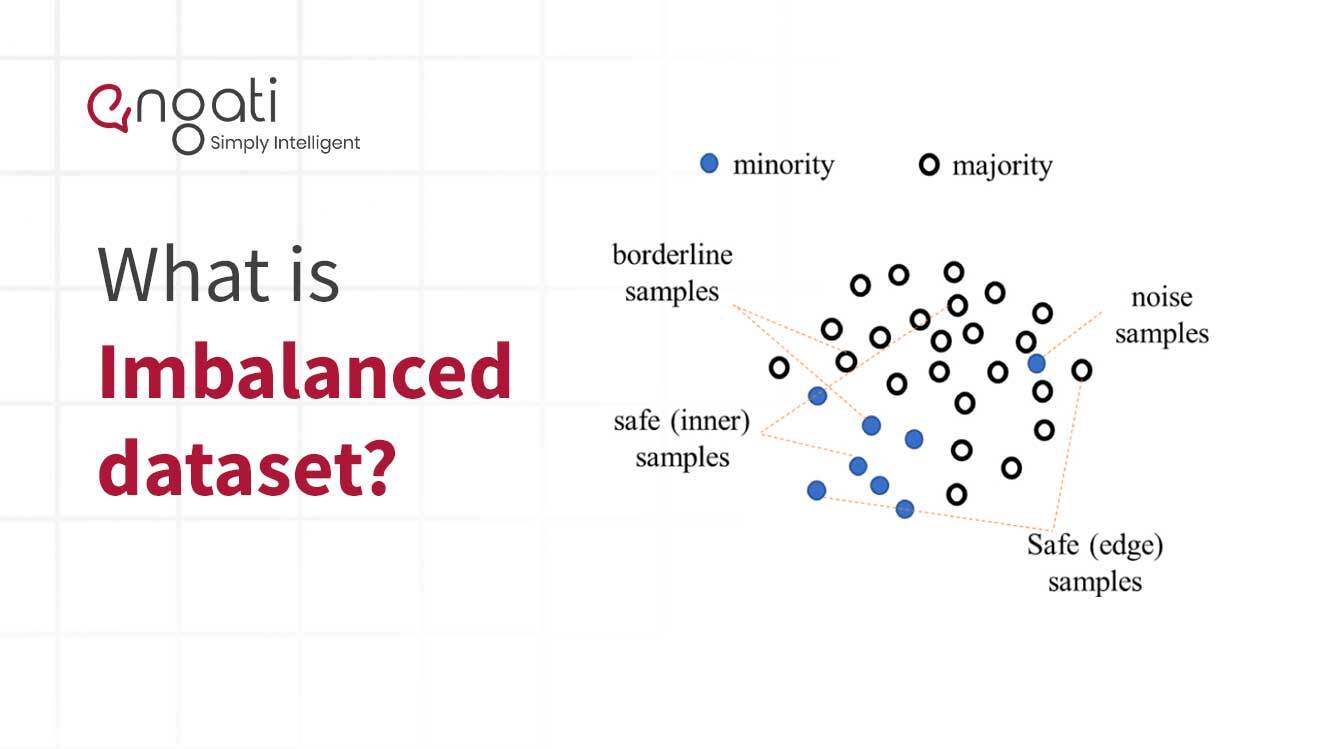
Nevyvážená data jsou typ dat, která mají nestejné zastoupení dvou nebo více tříd informací. Tento typ dat je běžný v oblasti strojového učení a prediktivní analytiky. Nastává, když je množství jedné třídy datových bodů výrazně vyšší než množství všech ostatních tříd.
Nevyvážená data mohou být výzvou pro algoritmy strojového učení. Pokud ukázková data obsahují příliš mnoho nebo příliš málo jedné třídy datových bodů, nemusí být algoritmus schopen správně detekovat vzory. V důsledku toho mohou být předpovědi provedené algoritmem nepřesné. Aby bylo zajištěno, že model je přesnější, musí být data vyvážena, aby bylo zajištěno, že všechny třídy budou mít podobné zastoupení.
Pro vyvážení dat lze použít techniky vzorkování dat, jako je převzorkování a podvzorkování. Při převzorkování se do vzorku přidá více datových bodů z třídy s menším zastoupením. Na druhou stranu podvzorkování je proces odstraňování datových bodů z třídy s větším zastoupením. Vyvážením datové sady mohou algoritmy strojového učení vytvářet lepší modely a přesnější předpovědi.
Nevyvážená data mohou mít hluboký dopad na datové sady používané ve strojovém učení. Proto je důležité podniknout kroky k zajištění vyváženosti použitých datových souborů, aby bylo možné vytvořit spolehlivé modely a získat přesné výsledky.