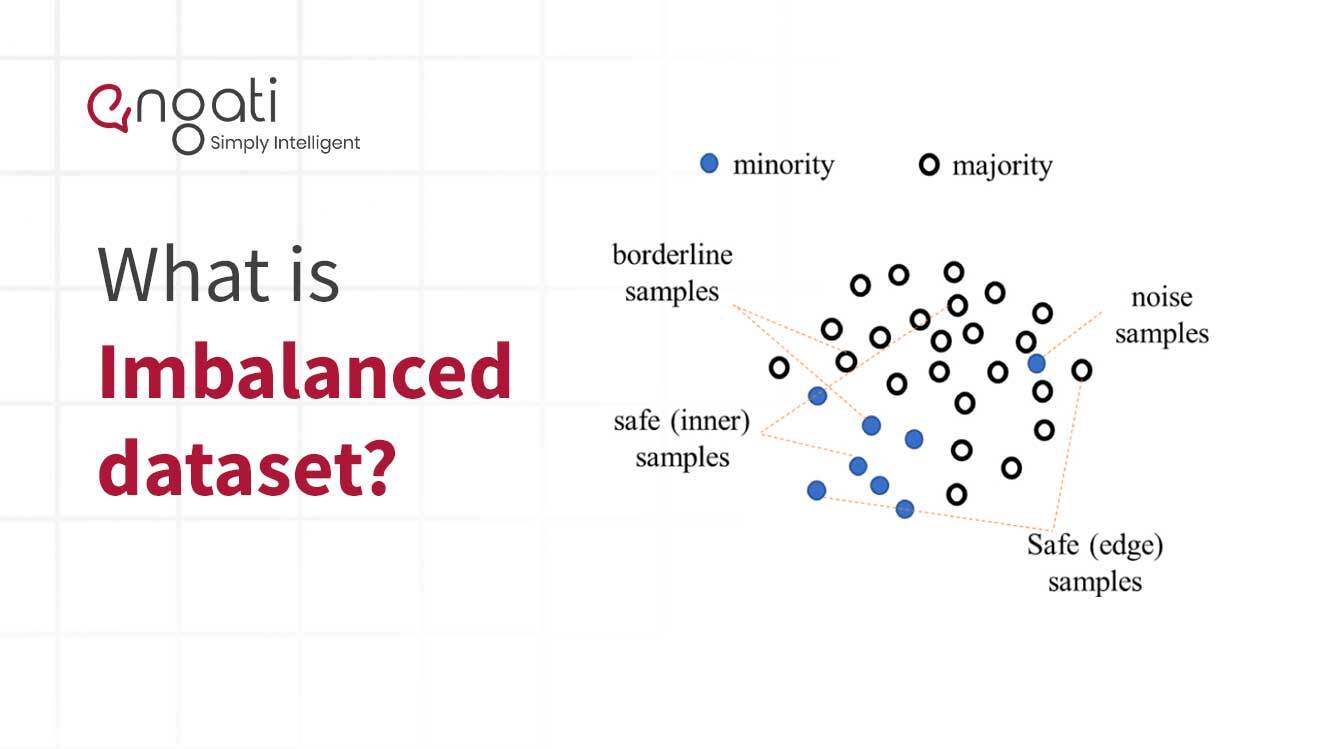
Les données déséquilibrées sont un type de données qui présentent une représentation inégale de deux classes d'informations ou plus. Ce type de données est courant dans le domaine de l'apprentissage automatique et de l'analyse prédictive. Il se produit lorsque la quantité d'une classe de points de données est significativement plus élevée que la quantité de toutes les autres classes.
Les données déséquilibrées peuvent constituer un défi pour les algorithmes d'apprentissage automatique. Lorsque l'échantillon de données contient trop ou trop peu de points de données d'une classe, l'algorithme peut ne pas être en mesure de détecter correctement les modèles. Par conséquent, les prédictions faites par l'algorithme peuvent être inexactes. Pour s'assurer que le modèle est plus précis, les données doivent être équilibrées afin de garantir que toutes les classes ont une représentation similaire.
Pour équilibrer les données, il est possible d'utiliser des techniques d'échantillonnage telles que le suréchantillonnage et le sous-échantillonnage. Dans le cas du suréchantillonnage, on ajoute à l'échantillon des points de données de la classe la moins représentée. En revanche, le sous-échantillonnage consiste à retirer des points de données de la classe la plus représentée. En équilibrant l'ensemble des données, les algorithmes d'apprentissage automatique peuvent créer de meilleurs modèles et faire des prédictions plus précises.
Les données déséquilibrées peuvent avoir un impact profond sur les ensembles de données utilisés dans l'apprentissage automatique. Il est donc important de prendre des mesures pour s'assurer que les ensembles de données utilisés sont équilibrés afin de créer des modèles fiables et d'obtenir des résultats précis.