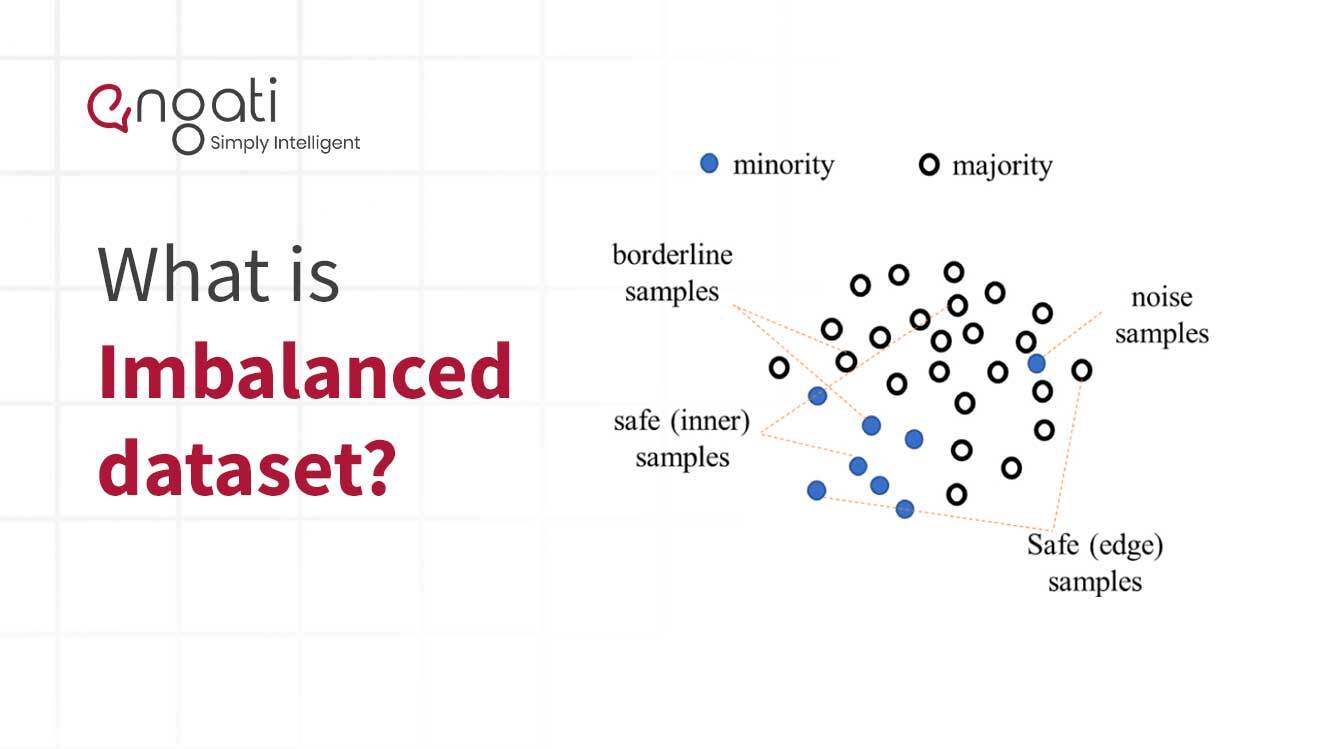
不平衡数据是一种数据类型,它对两类或更多的信息有不平等的表述。这种类型的数据在机器学习和预测分析领域很常见。当一类数据点的数量明显高于所有其他类别的数量时,就会出现这种情况。
不平衡的数据对机器学习算法是一个挑战。当样本数据中包含过多或过少的一类数据点时,算法可能无法正确检测到这些模式。因此,算法做出的预测可能是不准确的。为了确保模型更加准确,必须对数据进行平衡,以确保所有类别都有类似的代表性。
为了平衡数据,人们可以使用数据抽样技术,如超额抽样和欠额抽样。在过度取样中,从代表性较低的类别中添加更多的数据点到样本中。另一方面,欠抽样是指从具有更多代表性的类别中删除数据点的过程。通过平衡数据集,机器学习算法可以创建更好的模型,做出更准确的预测。
不平衡的数据会对用于机器学习的数据集产生深远的影响。因此,必须采取措施,确保所使用的数据集是平衡的,以创建可靠的模型并获得准确的结果。