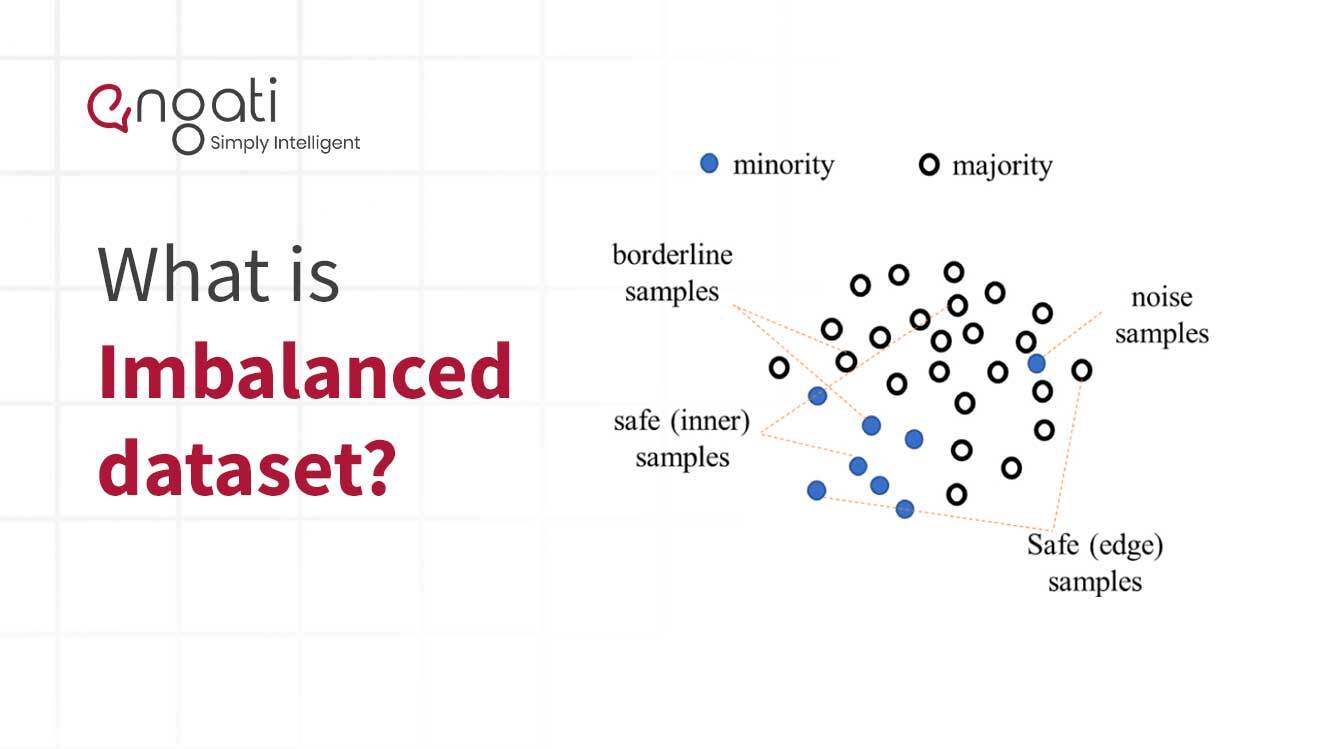
불균형 데이터는 두 가지 이상의 정보 클래스가 불균등하게 표현된 데이터 유형입니다. 이러한 유형의 데이터는 머신 러닝 및 예측 분석 분야에서 흔히 발생합니다. 한 데이터 요소 클래스의 수량이 다른 모든 클래스의 수량보다 훨씬 많을 때 발생합니다.
불균형한 데이터는 머신러닝 알고리즘에 문제가 될 수 있습니다. 샘플 데이터에 한 종류의 데이터 포인트가 너무 많거나 너무 적으면 알고리즘이 패턴을 올바르게 감지하지 못할 수 있습니다. 결과적으로 알고리즘의 예측이 부정확할 수 있습니다. 모델의 정확도를 높이려면 모든 클래스가 유사한 표현을 갖도록 데이터의 균형을 맞춰야 합니다.
데이터 균형을 맞추기 위해 오버샘플링 및 언더샘플링과 같은 데이터 샘플링 기법을 사용할 수 있습니다. 오버샘플링에서는 대표성이 낮은 클래스의 데이터 포인트가 샘플에 더 많이 추가됩니다. 반면에 언더샘플링은 대표성이 더 높은 클래스에서 데이터 포인트를 제거하는 프로세스입니다. 데이터 세트의 균형을 맞추면 머신러닝 알고리즘은 더 나은 모델을 만들고 더 정확한 예측을 할 수 있습니다.
불균형한 데이터는 머신러닝에 사용되는 데이터 세트에 큰 영향을 미칠 수 있습니다. 따라서 신뢰할 수 있는 모델을 만들고 정확한 결과를 얻으려면 사용되는 데이터 세트의 균형을 맞추는 조치를 취하는 것이 중요합니다.