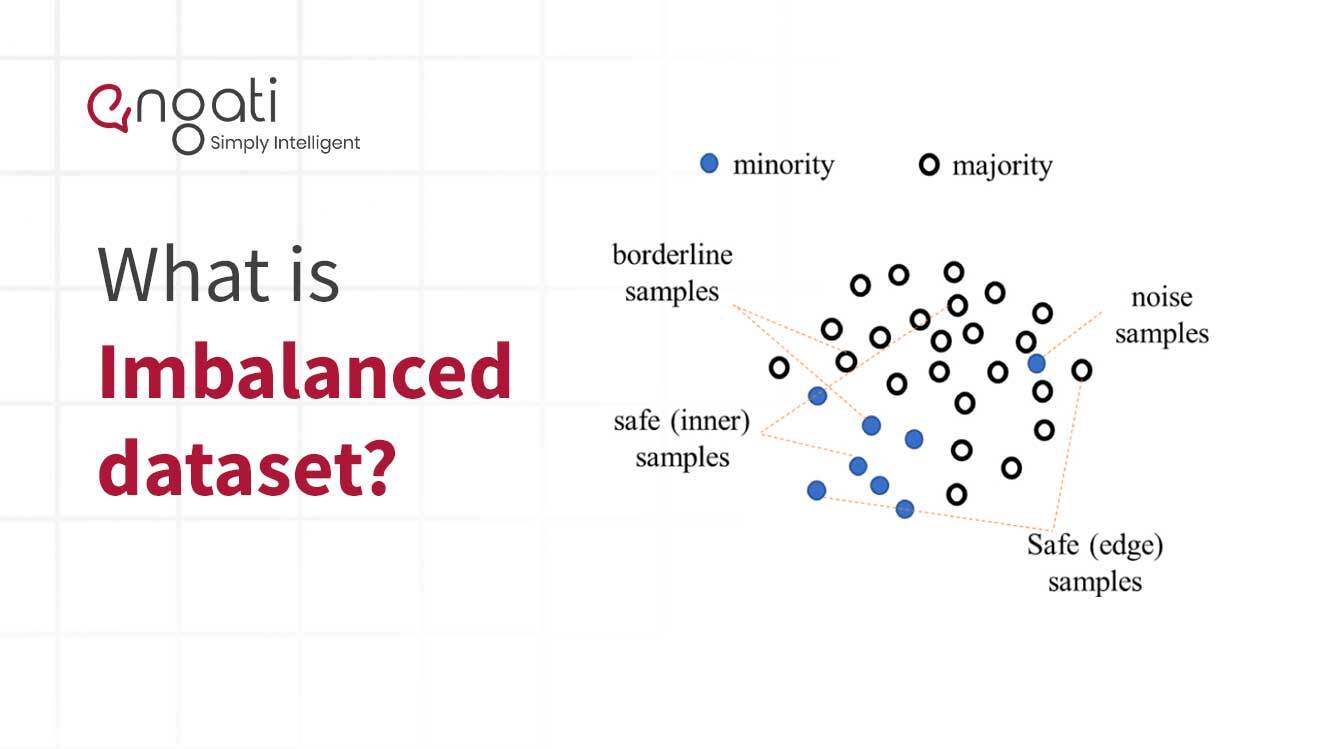
Imbalanced data is a type of data that has unequal representation of two or more classes of information. This type of data is common in the field of machine learning and predictive analytics. It occurs when the quantity of one class of data points is significantly higher than the quantity of all the other class.
Imbalanced data can be a challenge to machine learning algorithms. When the sample data contains too many or too few of one class of data points, the algorithm may not be able to detect the patterns correctly. As a result, the predictions made by the algorithm may be inaccurate. In order to make sure that the model is more accurate, data must be balanced in order to ensure that all classes have a similar representation.
In order to balance data, one can use data sampling techniques such as oversampling and undersampling. In oversampling, more data points from the class with less representation are added to the sample. On the other hand, undersampling is the process of removing data points from the class with more representation. By balancing the data set, machine learning algorithms can create better models and make more accurate predictions.
Imbalanced data can have a profound impact on datasets used in machine learning. As such, it is important to take steps to ensure that the data sets used are balanced in order to create reliable models and obtain accurate results.