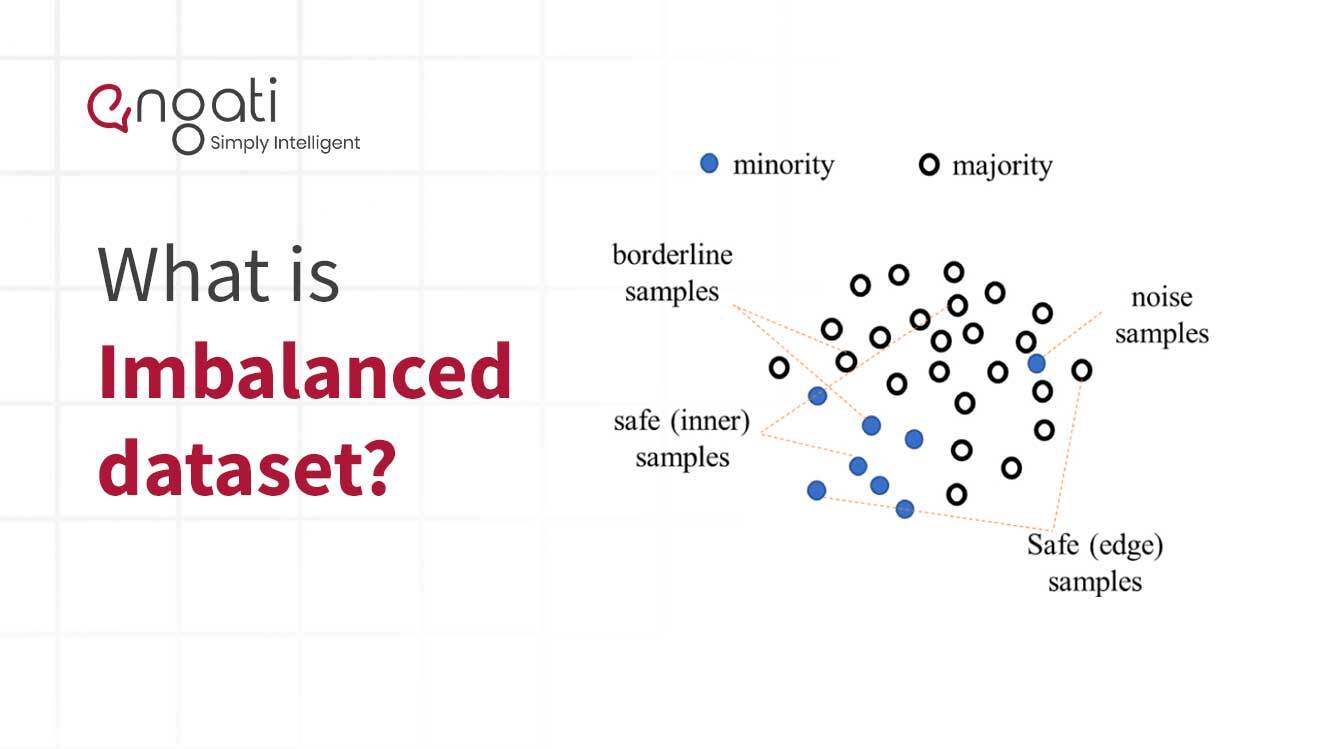
Los datos desequilibrados son un tipo de datos que tienen una representación desigual de dos o más clases de información. Este tipo de datos es común en el campo del aprendizaje automático y el análisis predictivo. Se produce cuando la cantidad de puntos de datos de una clase es significativamente mayor que la cantidad de todos los de la otra clase.
Los datos desequilibrados pueden ser un reto para los algoritmos de aprendizaje automático. Cuando los datos de muestra contienen demasiados o muy pocos puntos de una clase de datos, es posible que el algoritmo no pueda detectar los patrones correctamente. Como resultado, las predicciones realizadas por el algoritmo pueden ser inexactas. Para que el modelo sea más preciso, los datos deben estar equilibrados para garantizar que todas las clases tengan una representación similar.
Para equilibrar los datos, se pueden utilizar técnicas de muestreo de datos como el sobremuestreo y el submuestreo. En el sobremuestreo, se añaden a la muestra más puntos de datos de la clase con menos representación. Por otro lado, el submuestreo es el proceso de eliminar puntos de datos de la clase con más representación. Al equilibrar el conjunto de datos, los algoritmos de aprendizaje automático pueden crear mejores modelos y hacer predicciones más precisas.
Los datos desequilibrados pueden tener un profundo impacto en los conjuntos de datos utilizados en el aprendizaje automático. Por ello, es importante tomar medidas para garantizar que los conjuntos de datos utilizados estén equilibrados a fin de crear modelos fiables y obtener resultados precisos.