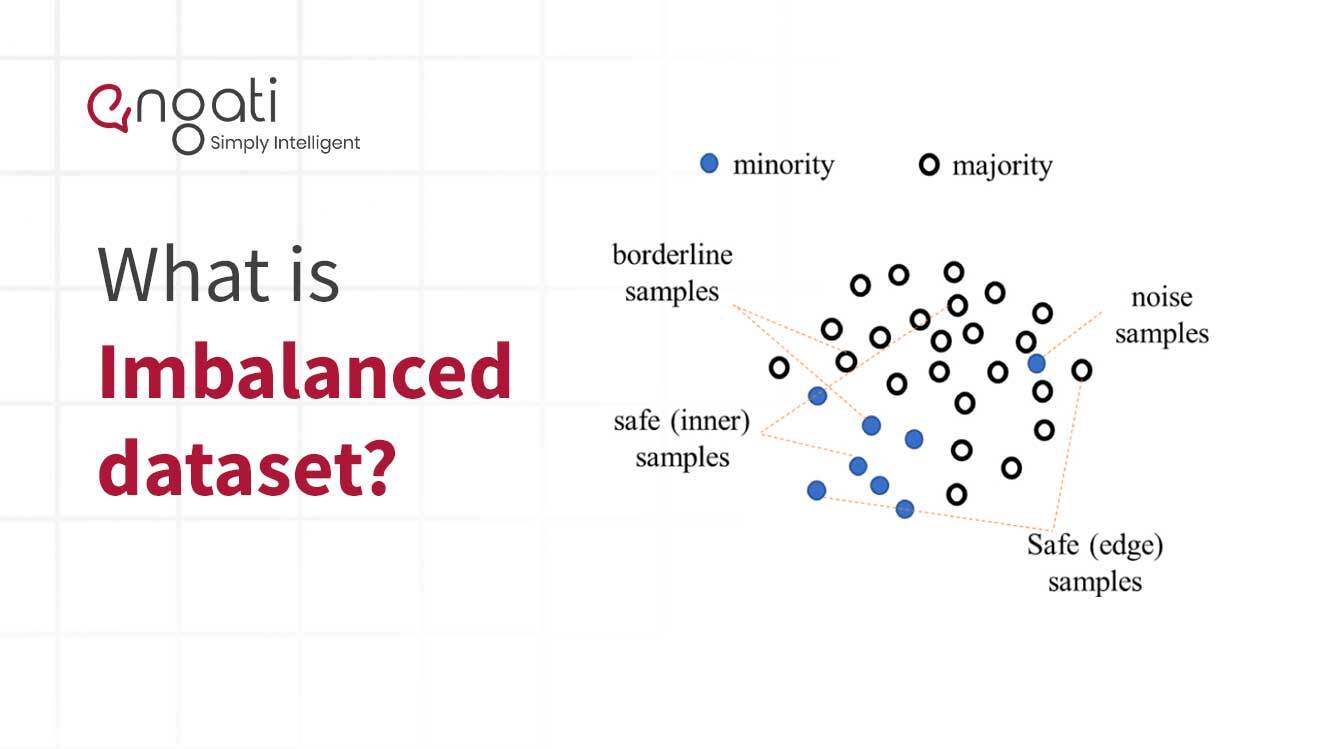
Niezbilansowane dane to rodzaj danych, które mają nierówną reprezentację dwóch lub więcej klas informacji. Ten typ danych jest powszechny w dziedzinie uczenia maszynowego i analityki predykcyjnej. Występuje, gdy ilość jednej klasy punktów danych jest znacznie wyższa niż ilość wszystkich innych klas.
Niezrównoważone dane mogą stanowić wyzwanie dla algorytmów uczenia maszynowego. Gdy przykładowe dane zawierają zbyt wiele lub zbyt mało punktów jednej klasy danych, algorytm może nie być w stanie prawidłowo wykryć wzorców. W rezultacie przewidywania dokonane przez algorytm mogą być niedokładne. Aby upewnić się, że model jest dokładniejszy, dane muszą być zrównoważone, aby zapewnić, że wszystkie klasy mają podobną reprezentację.
Aby zrównoważyć dane, można użyć technik próbkowania danych, takich jak nadpróbkowanie i niedostateczne próbkowanie. W przypadku nadpróbkowania do próby dodaje się więcej punktów danych z klasy o mniejszej reprezentacji. Z drugiej strony, niedostateczne próbkowanie to proces usuwania punktów danych z klasy o większej reprezentacji. Równoważąc zestaw danych, algorytmy uczenia maszynowego mogą tworzyć lepsze modele i dokonywać dokładniejszych prognoz.
Niezrównoważone dane mogą mieć ogromny wpływ na zestawy danych wykorzystywane w uczeniu maszynowym. W związku z tym ważne jest, aby podjąć kroki w celu zapewnienia, że używane zestawy danych są zrównoważone w celu stworzenia wiarygodnych modeli i uzyskania dokładnych wyników.