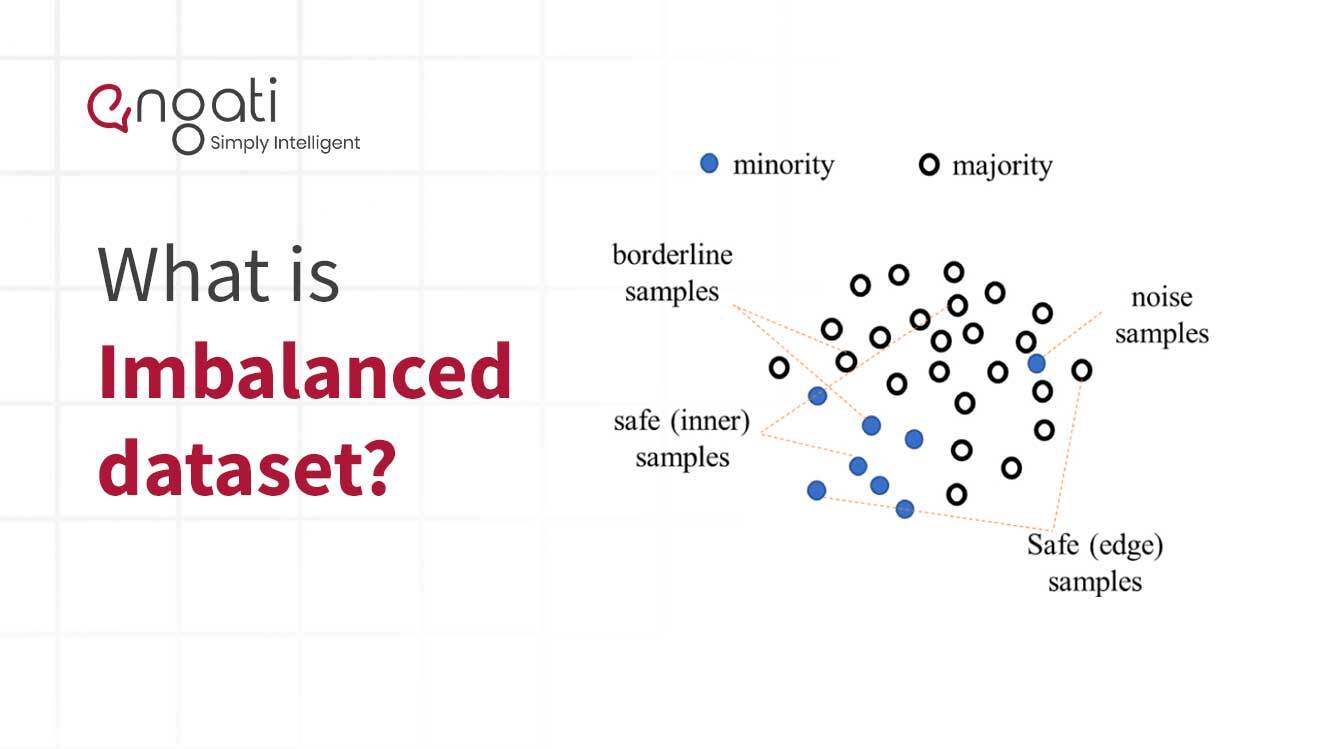
Onevenwichtige gegevens zijn gegevens waarbij twee of meer informatieklassen ongelijk vertegenwoordigd zijn. Dit type gegevens komt vaak voor bij machine learning en predictive analytics. Het doet zich voor wanneer de hoeveelheid van één klasse datapunten aanzienlijk groter is dan de hoeveelheid van alle andere klassen.
Onevenwichtige gegevens kunnen een uitdaging vormen voor algoritmen voor machinaal leren. Als de voorbeeldgegevens te veel of te weinig datapunten van één klasse bevatten, kan het algoritme de patronen mogelijk niet correct detecteren. Als gevolg daarvan kunnen de voorspellingen van het algoritme onnauwkeurig zijn. Om ervoor te zorgen dat het model nauwkeuriger is, moeten gegevens gebalanceerd worden om ervoor te zorgen dat alle klassen een vergelijkbare vertegenwoordiging hebben.
Om gegevens in evenwicht te brengen, kan gebruik worden gemaakt van steekproeftechnieken zoals oversampling en undersampling. Bij oversampling worden meer datapunten uit de klasse met minder vertegenwoordiging toegevoegd aan de steekproef. Aan de andere kant is undersampling het proces van het verwijderen van datapunten uit de klasse met meer representatie. Door de gegevensverzameling in evenwicht te brengen, kunnen algoritmen voor machinaal leren betere modellen maken en nauwkeurigere voorspellingen doen.
Onevenwichtige gegevens kunnen een grote invloed hebben op datasets die worden gebruikt bij machine learning. Daarom is het belangrijk stappen te ondernemen om ervoor te zorgen dat de gebruikte datasets gebalanceerd zijn om betrouwbare modellen te maken en nauwkeurige resultaten te verkrijgen.