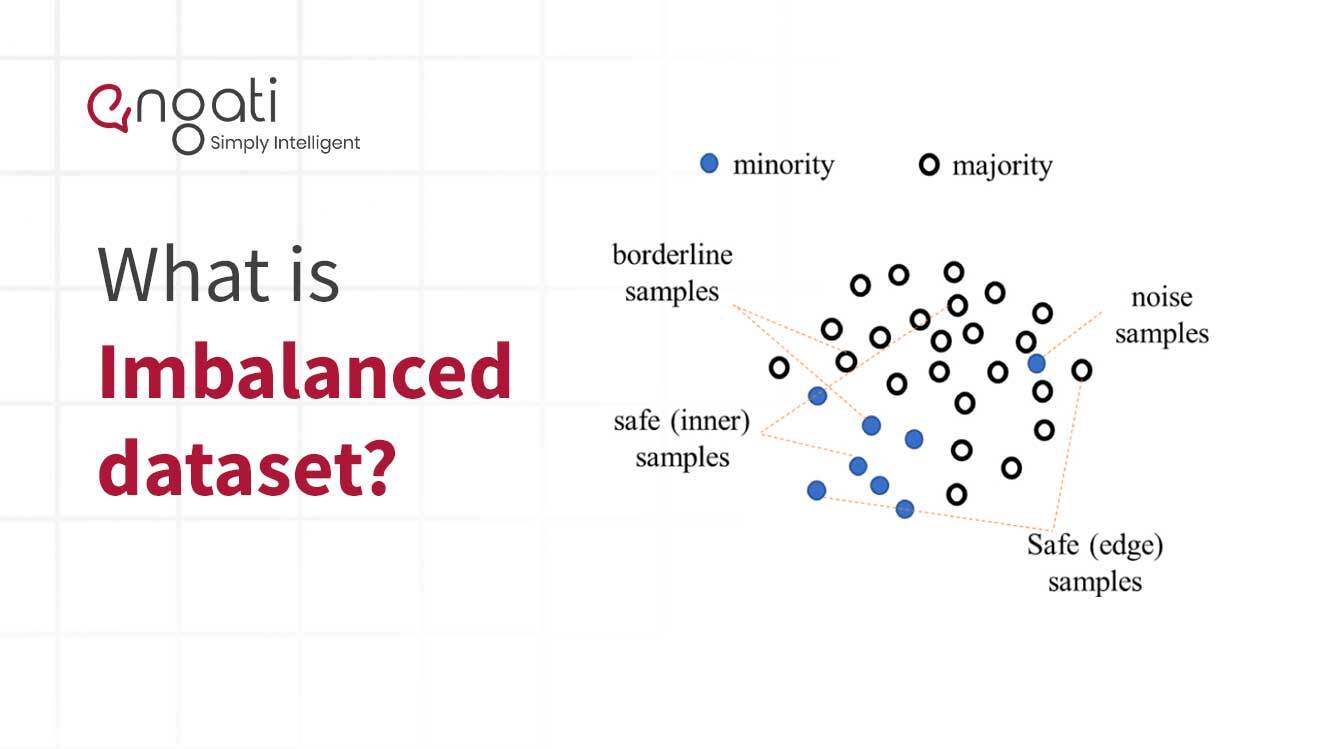
असंतुलित डेटा एक प्रकार का डेटा है जिसमें दो या दो से अधिक वर्गों की जानकारी का असमान प्रतिनिधित्व होता है। इस प्रकार का डेटा मशीन लर्निंग और प्रेडिक्टिव एनालिटिक्स के क्षेत्र में आम है। यह तब होता है जब डेटा बिंदुओं के एक वर्ग की मात्रा अन्य सभी वर्गों की मात्रा से काफी अधिक होती है।
असंतुलित डेटा मशीन लर्निंग एल्गोरिदम के लिए एक चुनौती हो सकता है। जब नमूना डेटा में डेटा बिंदुओं के एक वर्ग में बहुत अधिक या बहुत कम होते हैं, तो एल्गोरिदम पैटर्न का सही ढंग से पता लगाने में सक्षम नहीं हो सकता है। परिणामस्वरूप, एल्गोरिथम द्वारा की गई भविष्यवाणियाँ गलत हो सकती हैं। यह सुनिश्चित करने के लिए कि मॉडल अधिक सटीक है, डेटा को संतुलित किया जाना चाहिए ताकि यह सुनिश्चित किया जा सके कि सभी वर्गों का समान प्रतिनिधित्व हो।
डेटा को संतुलित करने के लिए, कोई डेटा सैंपलिंग तकनीकों जैसे ओवरसैंपलिंग और अंडरसैंपलिंग का उपयोग कर सकता है। ओवरसैंपलिंग में, कम प्रतिनिधित्व वाले वर्ग से अधिक डेटा बिंदु नमूने में जोड़े जाते हैं। दूसरी ओर, अंडरसैंपलिंग अधिक प्रतिनिधित्व वाले वर्ग से डेटा बिंदुओं को हटाने की प्रक्रिया है। डेटा सेट को संतुलित करके, मशीन लर्निंग एल्गोरिदम बेहतर मॉडल बना सकते हैं और अधिक सटीक भविष्यवाणियां कर सकते हैं।
असंतुलित डेटा मशीन लर्निंग में उपयोग किए जाने वाले डेटासेट पर गहरा प्रभाव डाल सकता है। ऐसे में, यह सुनिश्चित करने के लिए कदम उठाना महत्वपूर्ण है कि विश्वसनीय मॉडल बनाने और सटीक परिणाम प्राप्त करने के लिए उपयोग किए गए डेटा सेट संतुलित हैं।