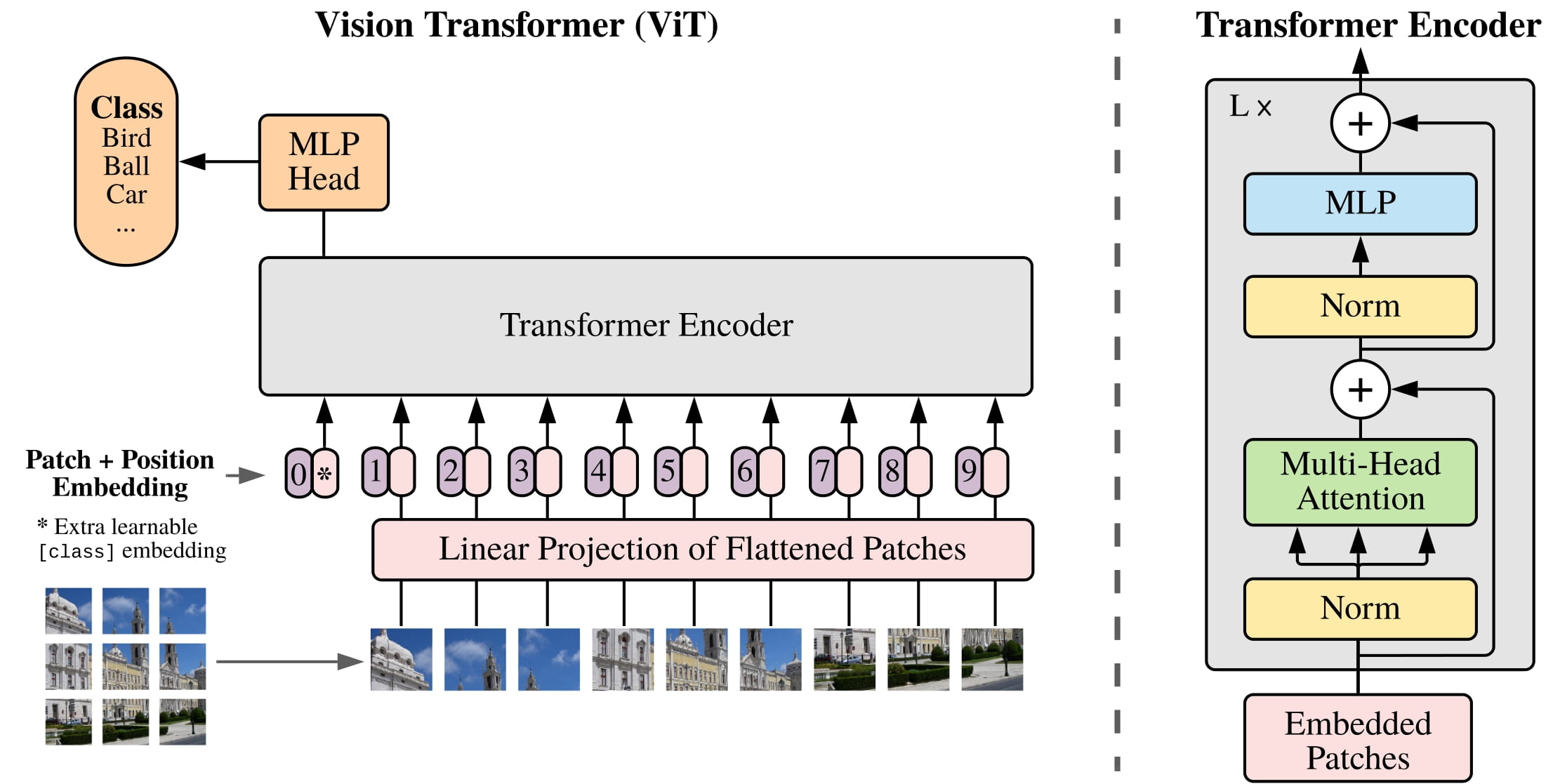
ViT (Vision Transformer) هو نوع من نظام رؤية الكمبيوتر القائم على التعلم العميق الذي طورته Google في عام 2020. وهو عبارة عن بنية قائمة على المحولات تعتمد على آليات الاهتمام المخصصة لمهام تصنيف الصور. تعتبر ViT أداة قوية لفهم البيانات المرئية، حيث أنها تسمح باستخراج الميزات على مستويات ومستويات تجريد مختلفة.
يتكون ViT من مكونين رئيسيين؛ شبكة الرؤية (ViT) وشبكة المحولات (ViT-T). يستخدم ViT مجموعة من الكتل التلافيفية لاستخراج ميزات الصورة وتمثيل الصور كمتجهات مميزة. تُستخدم شبكة المحولات لتحليل وتفسير الميزات التي تولدها شبكة الرؤية، مما يسمح بمهام تصنيف أكثر تعقيدًا.
تتميز ViT بقدرتها على التوسع في مجموعات البيانات الكبيرة، فضلاً عن قدرتها على التعلم من كميات صغيرة من البيانات. ويُنظر إليه على أنه إنجاز كبير في رؤية الكمبيوتر، لأنه يسمح بفهم أفضل للبيانات المرئية واسعة النطاق.
وقد شهدت شركة ViT بالفعل العديد من التطبيقات في مجالات مختلفة، مثل التصوير الطبي والروبوتات ومعالجة اللغات الطبيعية. كما تم استخدامه لتحسين وتحسين أنظمة رؤية الكمبيوتر الحالية.
يظهر ViT الكثير من الأمل في تطوير الآلات الذكية، لأنه يمكّن الآلات من تفسير البيانات المرئية المعقدة بطريقة أكثر دقة واتساقًا. ويمكن أن تلعب هذه التكنولوجيا دورًا أساسيًا في تطوير أنظمة الذكاء الاصطناعي والتعلم الآلي في المستقبل.