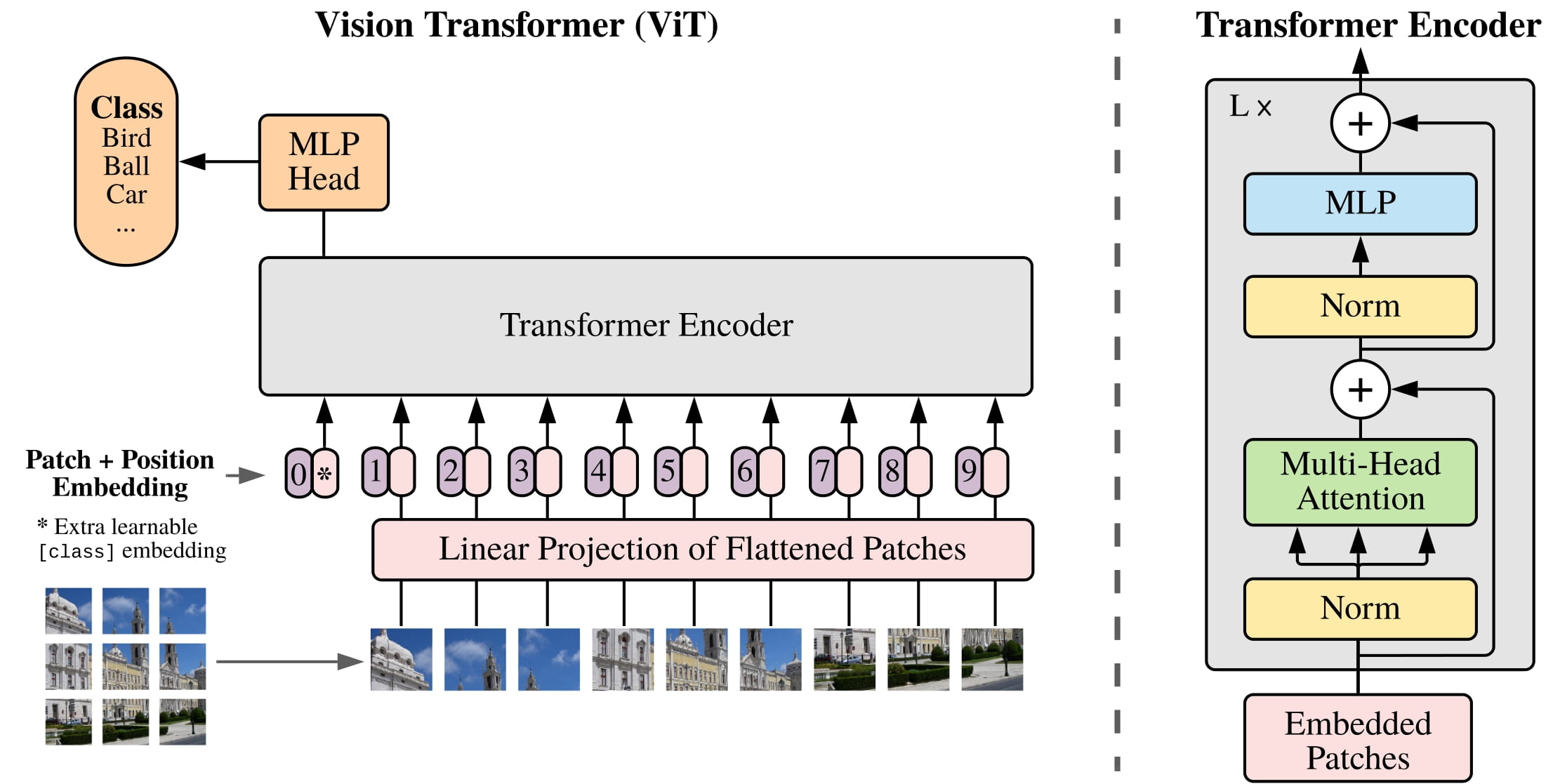
ViT (Vision Transformer) es un tipo de sistema de visión por ordenador basado en aprendizaje profundo desarrollado por Google en 2020. Se trata de una arquitectura basada en transformadores que se apoya en mecanismos de atención personalizados para tareas de clasificación de imágenes. ViT es una potente herramienta para comprender datos visuales, ya que permite extraer características a diferentes escalas y niveles de abstracción.
ViT consta de dos componentes principales: la red de visión (ViT) y la red de transformación (ViT-T). ViT utiliza una pila de bloques convolucionales para extraer características de las imágenes y representarlas como vectores de características. La red de transformación se utiliza para analizar e interpretar las características generadas por la red de visión, lo que permite realizar tareas de clasificación más complejas.
ViT destaca por su capacidad para escalar a grandes conjuntos de datos, así como por su capacidad para aprender a partir de pequeñas cantidades de datos. Se considera un gran avance en la visión por ordenador, ya que permite comprender mejor los datos visuales a gran escala.
ViT ya ha visto varias aplicaciones en diversos campos, como la imagen médica, la robótica y el procesamiento del lenguaje natural. También se ha utilizado para optimizar y mejorar sistemas de visión por ordenador ya existentes.
El ViT es muy prometedor para el desarrollo de máquinas inteligentes, ya que permite a las máquinas interpretar datos visuales complejos de forma más precisa y coherente. Esta tecnología podría desempeñar un papel integral en el desarrollo de sistemas de inteligencia artificial y aprendizaje automático en el futuro.