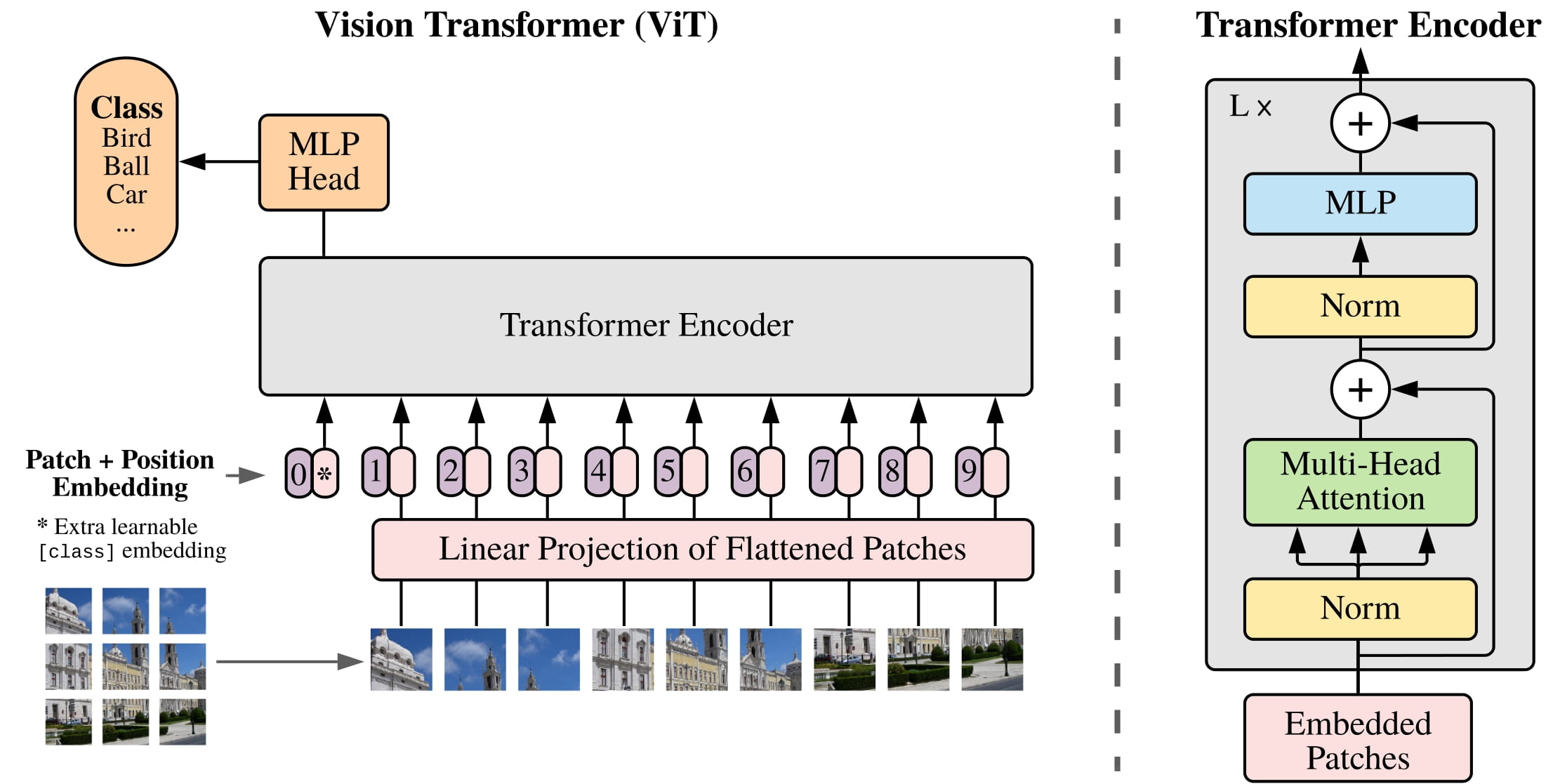
O ViT (Vision Transformer) é um tipo de sistema de visão computacional baseado em aprendizagem profunda desenvolvido pelo Google em 2020. Trata-se de uma arquitetura baseada em transformador que depende de mecanismos de atenção personalizados para tarefas de classificação de imagens. O ViT é uma ferramenta avançada para compreender dados visuais, pois permite a extração de recursos em diferentes escalas e níveis de abstração.
O ViT consiste em dois componentes principais: a Rede de Visão (ViT) e a Rede Transformadora (ViT-T). A ViT usa uma pilha de blocos convolucionais para extrair recursos de imagem e representar imagens como vetores de recursos. A Rede Transformadora é usada para analisar e interpretar os recursos gerados pela Rede de Visão, permitindo tarefas de classificação mais complexas.
O ViT é notável por sua capacidade de dimensionar grandes conjuntos de dados, bem como por sua capacidade de aprender com pequenas quantidades de dados. Ele é visto como um grande avanço na visão computacional, pois permite uma melhor compreensão dos dados visuais em grande escala.
A ViT já viu várias aplicações em diversos campos, como imagens médicas, robótica e processamento de linguagem natural. Ele também tem sido usado para otimizar e aprimorar os sistemas de visão computacional existentes.
A ViT é muito promissora para o desenvolvimento de máquinas inteligentes, pois permite que as máquinas interpretem dados visuais complexos de maneira mais precisa e consistente. Essa tecnologia poderá desempenhar um papel fundamental no desenvolvimento de inteligência artificial e sistemas de aprendizado de máquina no futuro.