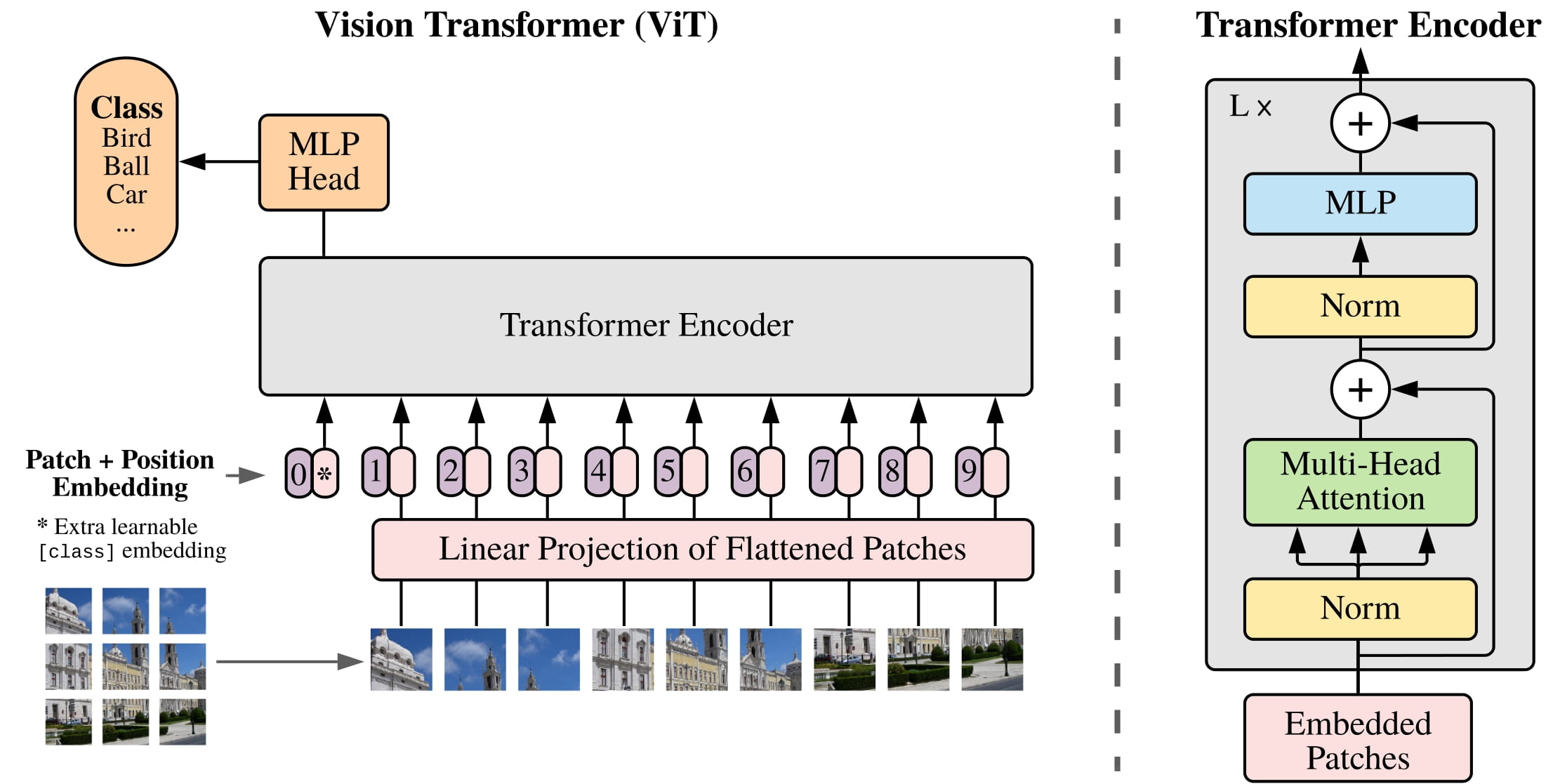
ViT (Vision Transformer) là một loại hệ thống thị giác máy tính dựa trên deep learning được Google phát triển vào năm 2020. Đây là một kiến trúc dựa trên máy biến áp dựa trên các cơ chế chú ý tùy chỉnh cho các tác vụ phân loại hình ảnh. ViT là một công cụ mạnh mẽ để hiểu dữ liệu trực quan vì nó cho phép trích xuất các tính năng ở các quy mô và mức độ trừu tượng khác nhau.
ViT bao gồm hai thành phần chính; Mạng Tầm nhìn (ViT) và Mạng Máy biến áp (ViT-T). ViT sử dụng một chồng các khối tích chập để trích xuất các đặc điểm của hình ảnh và biểu diễn hình ảnh dưới dạng vectơ đặc trưng. Mạng Máy biến áp được sử dụng để phân tích và diễn giải các tính năng do Mạng Tầm nhìn tạo ra, cho phép thực hiện các tác vụ phân loại phức tạp hơn.
ViT đáng chú ý vì khả năng mở rộng quy mô sang các tập dữ liệu lớn, cũng như khả năng học hỏi từ một lượng nhỏ dữ liệu. Nó được coi là một bước đột phá lớn trong lĩnh vực thị giác máy tính vì nó cho phép hiểu rõ hơn về dữ liệu hình ảnh quy mô lớn.
ViT đã thấy một số ứng dụng trong nhiều lĩnh vực khác nhau, chẳng hạn như hình ảnh y tế, robot và xử lý ngôn ngữ tự nhiên. Nó cũng đã được sử dụng để tối ưu hóa và cải thiện các hệ thống thị giác máy tính hiện có.
ViT cho thấy nhiều hứa hẹn về sự phát triển của máy móc thông minh vì nó cho phép máy móc diễn giải dữ liệu hình ảnh phức tạp một cách chính xác và nhất quán hơn. Công nghệ này có thể đóng một vai trò không thể thiếu trong việc phát triển trí tuệ nhân tạo và hệ thống máy học trong tương lai.