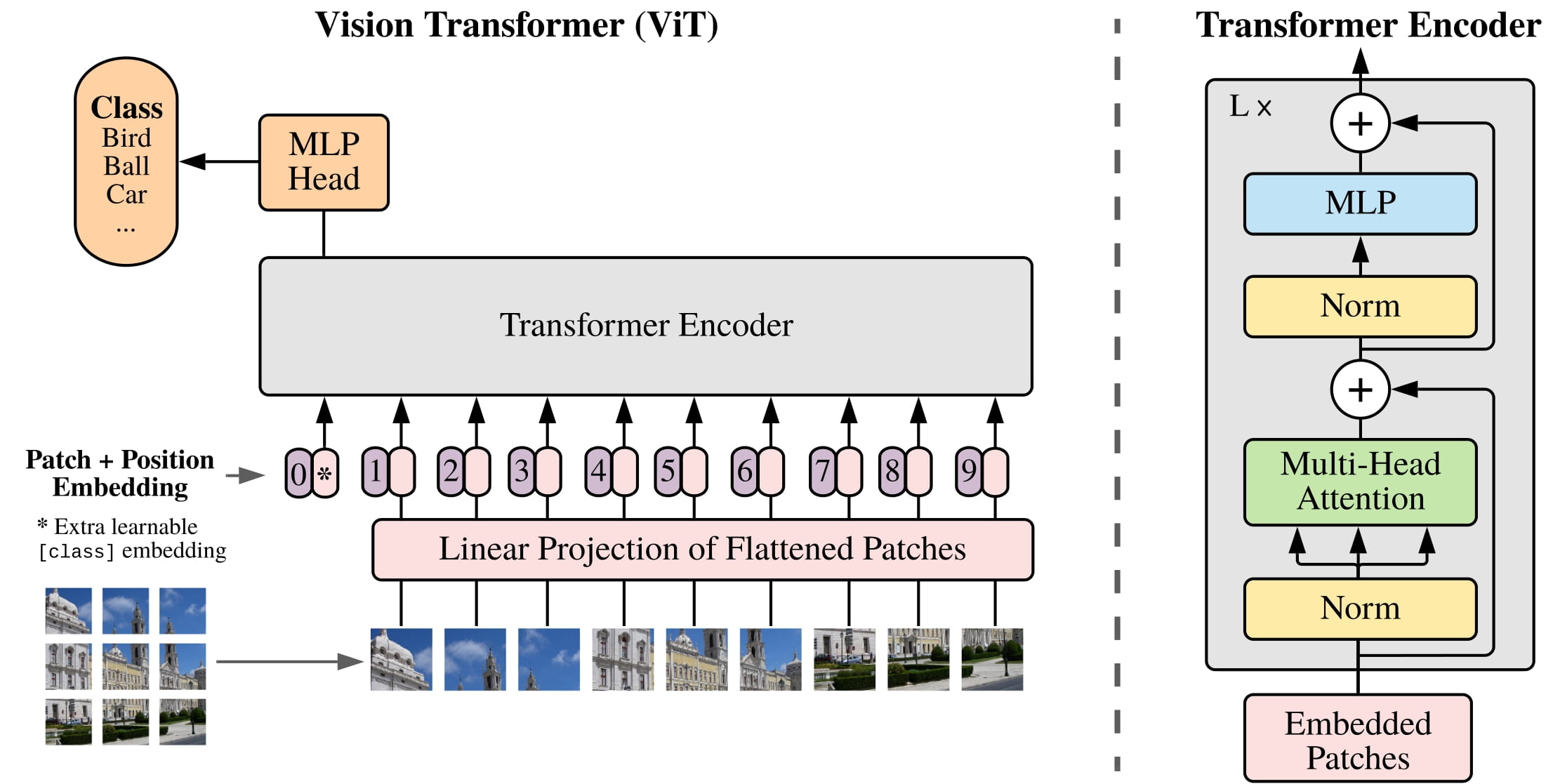
ViT (Vision Transformer) - это тип системы компьютерного зрения на основе глубокого обучения, разработанный компанией Google в 2020 году. Это архитектура на основе трансформатора, которая опирается на специализированные механизмы внимания для задач классификации изображений. ViT - это мощный инструмент для понимания визуальных данных, поскольку он позволяет извлекать признаки на разных масштабах и уровнях абстракции.
ViT состоит из двух основных компонентов: сети видения (ViT) и сети преобразования (ViT-T). ViT использует стек сверточных блоков для извлечения характеристик изображения и представления изображений в виде векторов характеристик. Трансформирующая сеть используется для анализа и интерпретации признаков, генерируемых сетью технического зрения, что позволяет решать более сложные задачи классификации.
ViT отличается своей способностью масштабироваться на большие массивы данных, а также способностью обучаться на небольших объемах данных. Это считается большим прорывом в компьютерном зрении, поскольку позволяет лучше понимать крупномасштабные визуальные данные.
ViT уже получил несколько применений в различных областях, таких как медицинская визуализация, робототехника и обработка естественного языка. Он также используется для оптимизации и улучшения существующих систем компьютерного зрения.
ViT открывает большие перспективы для развития интеллектуальных машин, поскольку позволяет машинам интерпретировать сложные визуальные данные более точным и последовательным образом. В будущем эта технология может сыграть важную роль в развитии искусственного интеллекта и систем машинного обучения.