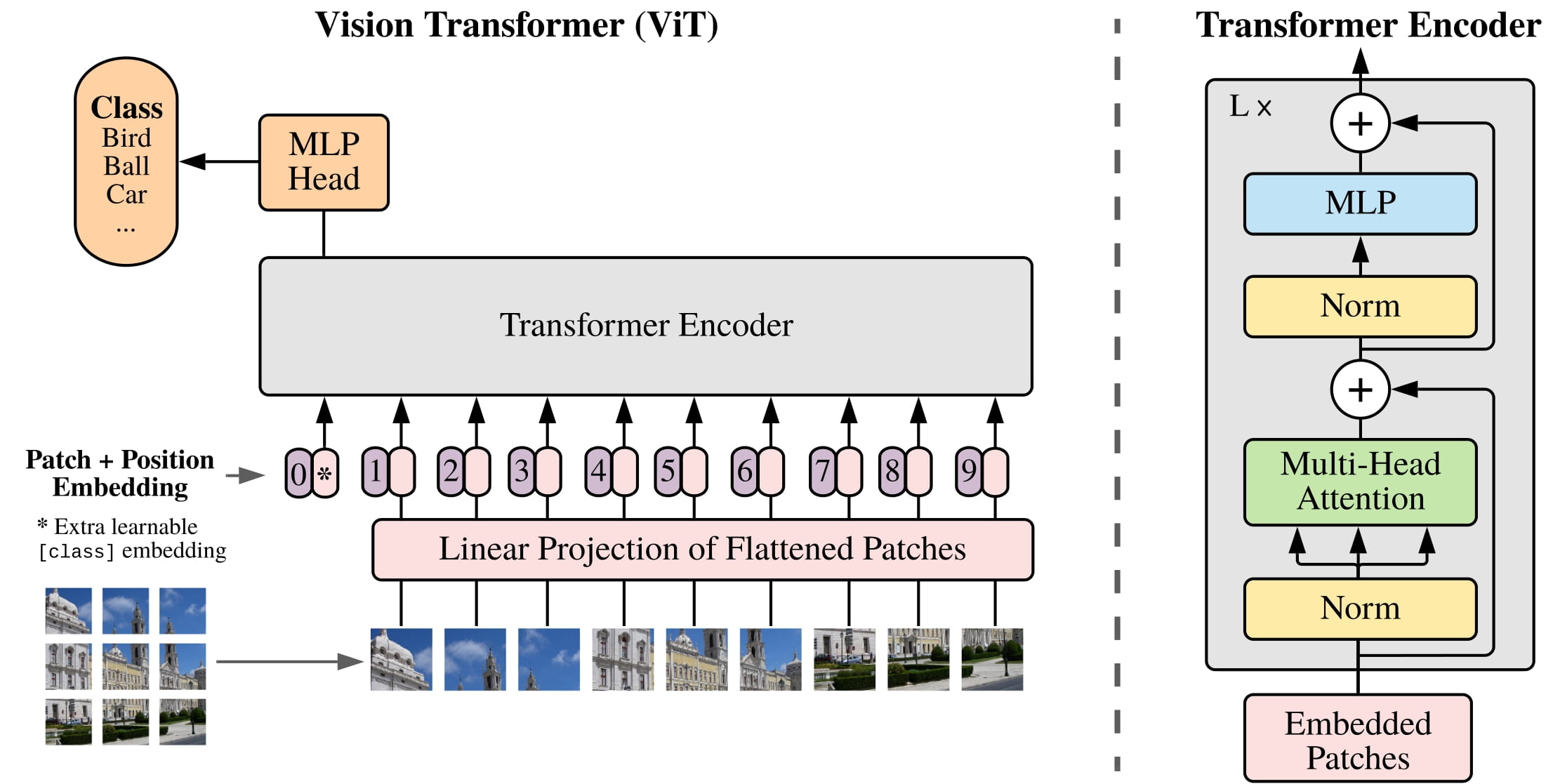
ViT (Vision Transformer) is a type of deep learning-based computer vision system developed by Google in 2020. It is a transformer-based architecture that relies on customized attention mechanisms for image classification tasks. ViT is a powerful tool for understanding visual data, as it allows for the extraction of features at different scales and abstraction levels.
ViT consists of two main components; the Vision Network (ViT) and the Transformer Network (ViT-T). ViT uses a stack of convolutional blocks to extract image features and represent images as feature vectors. The Transformer Network is used to analyze and interpret the features generated by the Vision Network, allowing for more complex classification tasks.
ViT is notable for its ability to scale to large datasets, as well as its ability to learn from small amounts of data. It is seen as a major breakthrough in computer vision, as it allows for better understanding of large-scale visual data.
ViT has already seen several applications in various fields, such as medical imaging, robotics, and natural language processing. It has also been used to optimize and improve existing computer vision systems.
ViT shows much promise for the development of intelligent machines, as it enables machines to interpret complex visual data in a more accurate and consistent manner. This technology could play an integral role in the development of artificial intelligence and machine learning systems in the future.