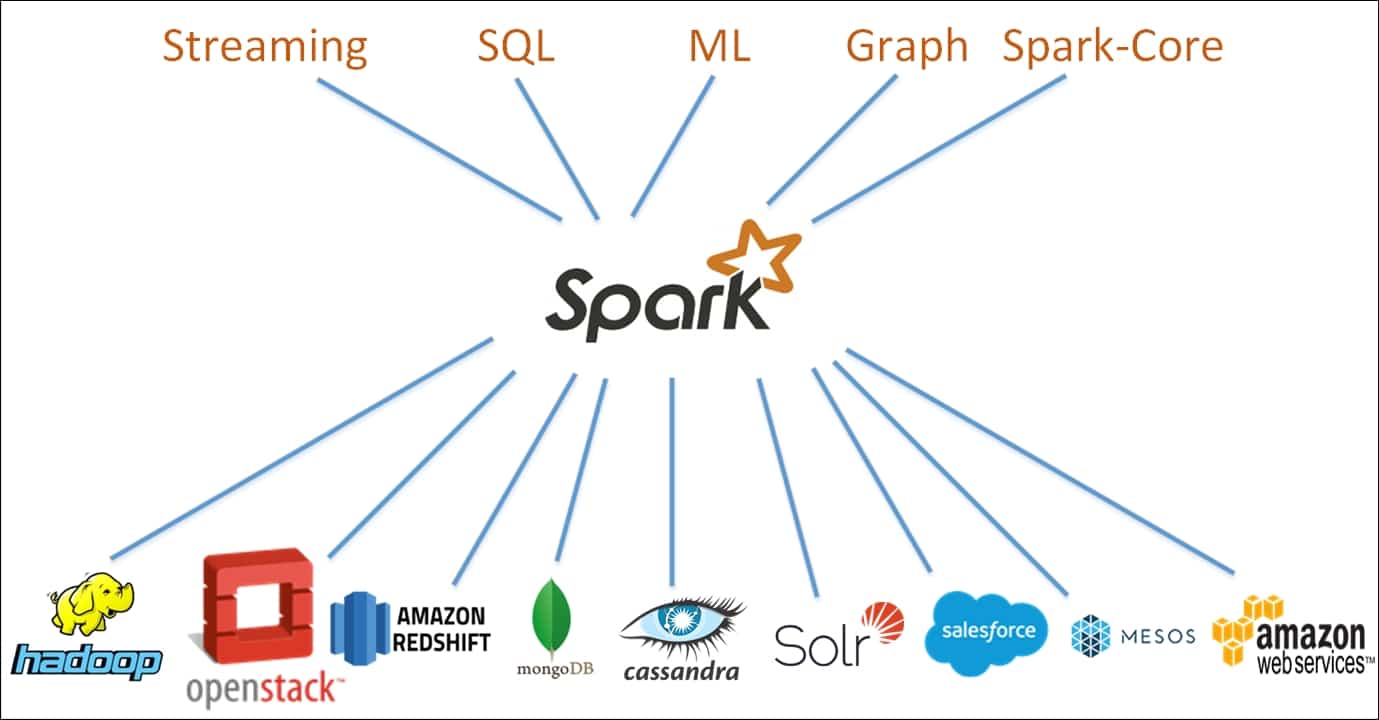
Apache Spark, basit ve verimli veri analitiği sağlamak için tasarlanmış ücretsiz ve açık kaynaklı bir dağıtık bilgi işlem çerçevesidir. Apache Yazılım Vakfı'nın bir projesi olarak geliştirilen Spark şu anda bellek içi veri işleme, etkileşimli sorgu işleme, akış işleme ve makine öğrenimi algoritmalarını desteklemektedir.
Apache Spark ilk olarak 2009 yılında veri analistlerine ve araştırmacılara Google tarafından geliştirilen ve yaygın olarak kullanılan MapReduce çerçevesine bir alternatif sunmak amacıyla piyasaya sürülmüştür. O zamandan bu yana Spark, dağıtık bilgi işlem ortamında bellek içi veri işleme çerçeveleri için fiili standart haline geldi.
Spark, tüm küme için denetleyici olarak hizmet veren bir ana düğüm ile bir küme hesaplama paradigması üzerine inşa edilmiştir. Kümedeki düğümler - veya "işçiler" - harici kaynaklardan veri okumaktan ve yazmaktan sorumludur. Spark mimarisi, her biri veri işlemeyi daha verimli ve güçlü hale getirmek için tasarlanmış birden fazla katmandan oluşur. Spark mimarisinin çekirdeği, verileri bir düğüm kümesinde depolayan dağıtılmış bir bellek kümesi olan Resilient Distributed Dataset'tir (RDD).
Spark, çeşitli veri işleme görevleri için uygun olmasını sağlayan çeşitli özellikler sunar. Bu özellikler arasında sorgu optimizasyonu, hata toleransı ve grafiksel kullanıcı arayüzleri yer alır. Ayrıca Spark, geliştiriciler için son derece esnek bir çerçeve sağlayarak kolaylıkla daha büyük kümelere ölçeklenecek şekilde tasarlanmıştır. Apache Spark çerçevesi tarafından sağlanan iskele, hem basit hem de karmaşık veri analitiği uygulamalarının tasarlanmasını kolaylaştırır.
Apache Spark, büyük veri kümeleriyle çalışan veri bilimciler için güçlü bir araç olarak giderek daha popüler hale geliyor. Ayrıca Spark, gerçek zamanlı büyük veri analitiği, makine öğrenimi ve doğal dil işleme için yaygın olarak kullanılmaktadır. Son olarak, ölçeklenebilirliği ve sağlam özellik seti nedeniyle Spark, çok çeşitli tahmine dayalı analitik uygulamaları geliştirmek için kullanılmaktadır.
Genel olarak Apache Spark, veri analizi ve makine öğrenimi için güçlü bir dağıtık bilgi işlem çerçevesidir ve büyük ölçekli veri analizi projeleri için güçlü ve çok yönlü bir çözüm arayan geliştiriciler için hızla tercih edilen bir platform haline gelmektedir.