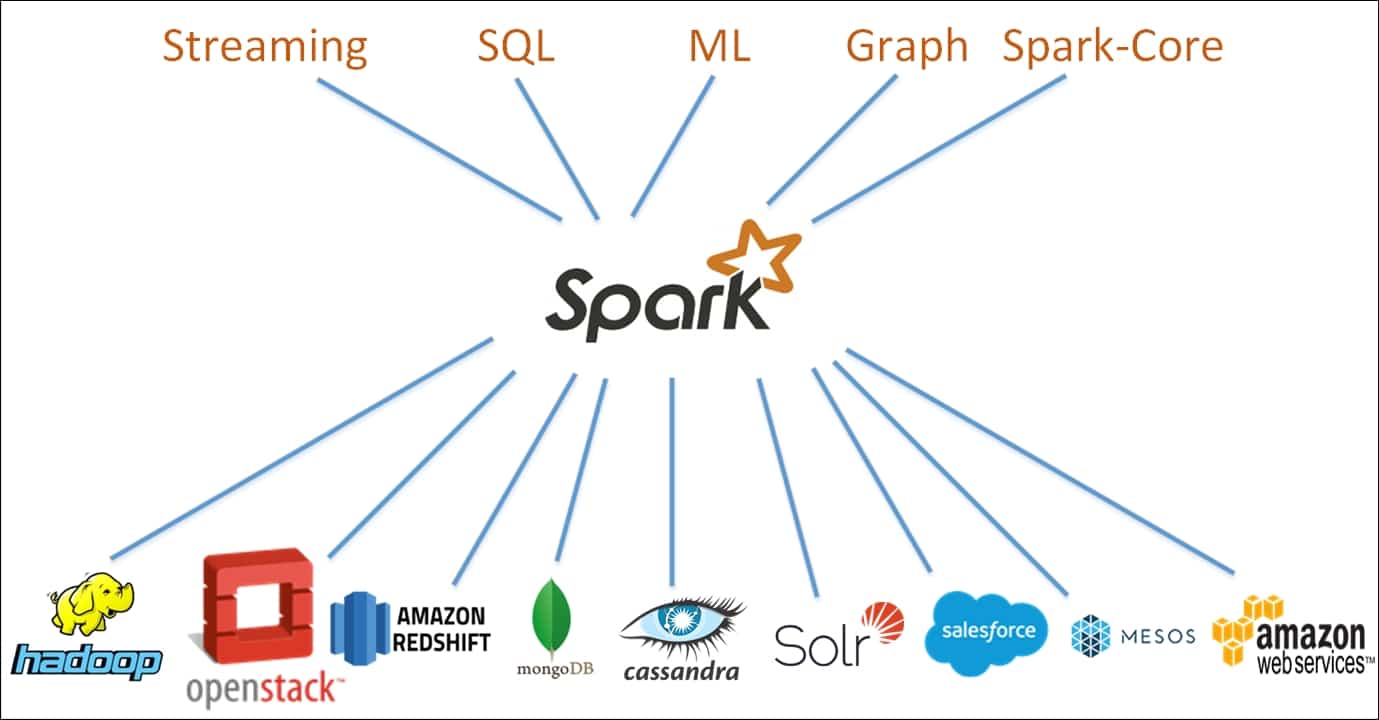
Apache Spark est un cadre informatique distribué, gratuit et open-source, conçu pour permettre une analyse simple et efficace des données. Développé dans le cadre d'un projet de l'Apache Software Foundation, Spark prend actuellement en charge le traitement des données en mémoire, le traitement interactif des requêtes, le traitement des flux et les algorithmes d'apprentissage automatique.
Apache Spark a été lancé en 2009 dans le but de fournir aux analystes de données et aux chercheurs une alternative au cadre MapReduce couramment utilisé et développé par Google. Depuis, Spark est devenu la norme de facto pour les cadres de traitement des données en mémoire dans le paysage informatique distribué.
Spark repose sur un paradigme d'informatique en grappe, avec un nœud maître servant de contrôleur pour l'ensemble de la grappe. Les nœuds - ou "travailleurs" - du cluster sont responsables de la lecture et de l'écriture des données provenant de sources externes. L'architecture Spark est composée de plusieurs couches, chacune conçue pour rendre le traitement des données plus efficace et plus puissant. Le cœur de l'architecture Spark est le Resilient Distributed Dataset (RDD), une grappe de mémoire distribuée qui stocke les données dans une grappe de nœuds.
Spark offre un grand nombre de fonctionnalités qui lui permettent de s'adapter à un grand nombre de tâches de traitement de données. Ces fonctionnalités comprennent l'optimisation des requêtes, la tolérance aux pannes et les interfaces utilisateur graphiques. De plus, Spark est conçu pour s'adapter facilement à des clusters plus importants, offrant ainsi aux développeurs un cadre très élastique. L'échafaudage fourni par le cadre Apache Spark facilite la conception d'applications d'analyse de données simples et complexes.
Apache Spark devient de plus en plus populaire en tant qu'outil puissant pour les scientifiques qui travaillent avec de grands ensembles de données. En outre, Spark est largement utilisé pour l'analyse des big data en temps réel, l'apprentissage automatique et le traitement du langage naturel. Enfin, grâce à son évolutivité et à son ensemble de fonctionnalités robustes, Spark est utilisé pour développer une gamme variée d'applications d'analyse prédictive.
Dans l'ensemble, Apache Spark est un puissant cadre de calcul distribué pour l'analyse de données et l'apprentissage automatique, et devient rapidement la plateforme de référence pour les développeurs à la recherche d'une solution puissante et polyvalente pour leurs projets d'analyse de données à grande échelle.