Apache Spark es un marco informático distribuido gratuito y de código abierto diseñado para permitir un análisis de datos sencillo y eficiente. Desarrollado como un proyecto de la Apache Software Foundation, Spark admite actualmente el procesamiento de datos en memoria, el procesamiento interactivo de consultas, el procesamiento de flujos y los algoritmos de aprendizaje automático.
Apache Spark se lanzó inicialmente en 2009 con el objetivo de proporcionar a los analistas de datos e investigadores una alternativa al marco MapReduce desarrollado por Google. Desde entonces, Spark se ha convertido en el estándar de facto para los marcos de procesamiento de datos en memoria en el panorama de la informática distribuida.
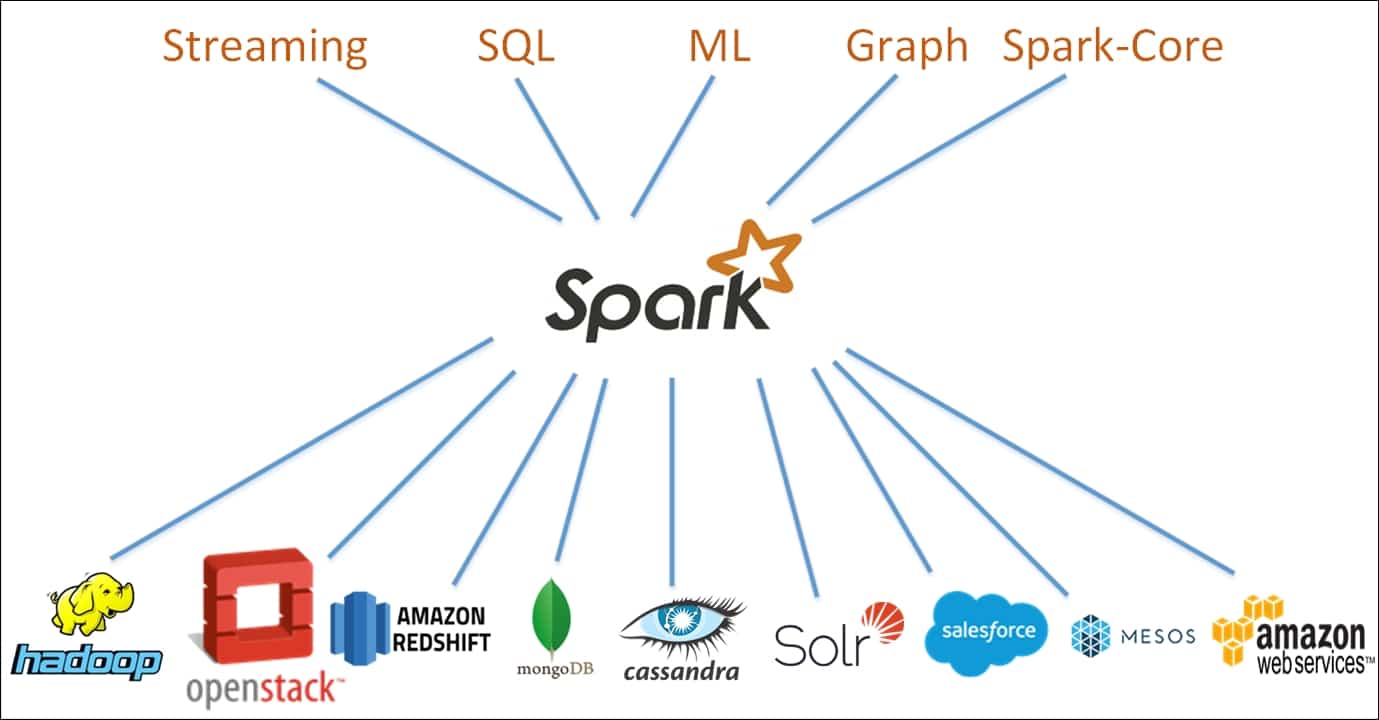
Spark se basa en un paradigma de computación en clúster, con un nodo maestro que actúa como controlador de todo el clúster. Los nodos -o "trabajadores"- del clúster se encargan de leer y escribir datos de fuentes externas. La arquitectura Spark se compone de múltiples capas, cada una de ellas diseñada para hacer más eficiente y potente el procesamiento de datos. El núcleo de la arquitectura Spark es el Resilient Distributed Dataset (RDD), un clúster de memoria distribuida que almacena datos en un clúster de nodos.
Spark ofrece una serie de características que lo hacen adecuado para diversas tareas de procesamiento de datos. Estas características incluyen optimización de consultas, tolerancia a fallos e interfaces gráficas de usuario. Además, Spark está diseñado para escalar a clusters más grandes con facilidad, proporcionando un marco altamente elástico para los desarrolladores. El andamiaje proporcionado por el marco Apache Spark facilita el diseño de aplicaciones de análisis de datos tanto sencillas como complejas.
Apache Spark es cada vez más popular como potente herramienta para los científicos de datos que trabajan con grandes conjuntos de datos. Además, Spark se está utilizando ampliamente para el análisis de big data en tiempo real, el aprendizaje automático y el procesamiento del lenguaje natural. Por último, debido a su escalabilidad y robustez, Spark se está utilizando para desarrollar una amplia gama de aplicaciones de análisis predictivo.
En general, Apache Spark es un potente marco de computación distribuida para el análisis de datos y el aprendizaje automático, y se está convirtiendo rápidamente en la plataforma de referencia para los desarrolladores que buscan una solución potente y versátil para sus proyectos de análisis de datos a gran escala.