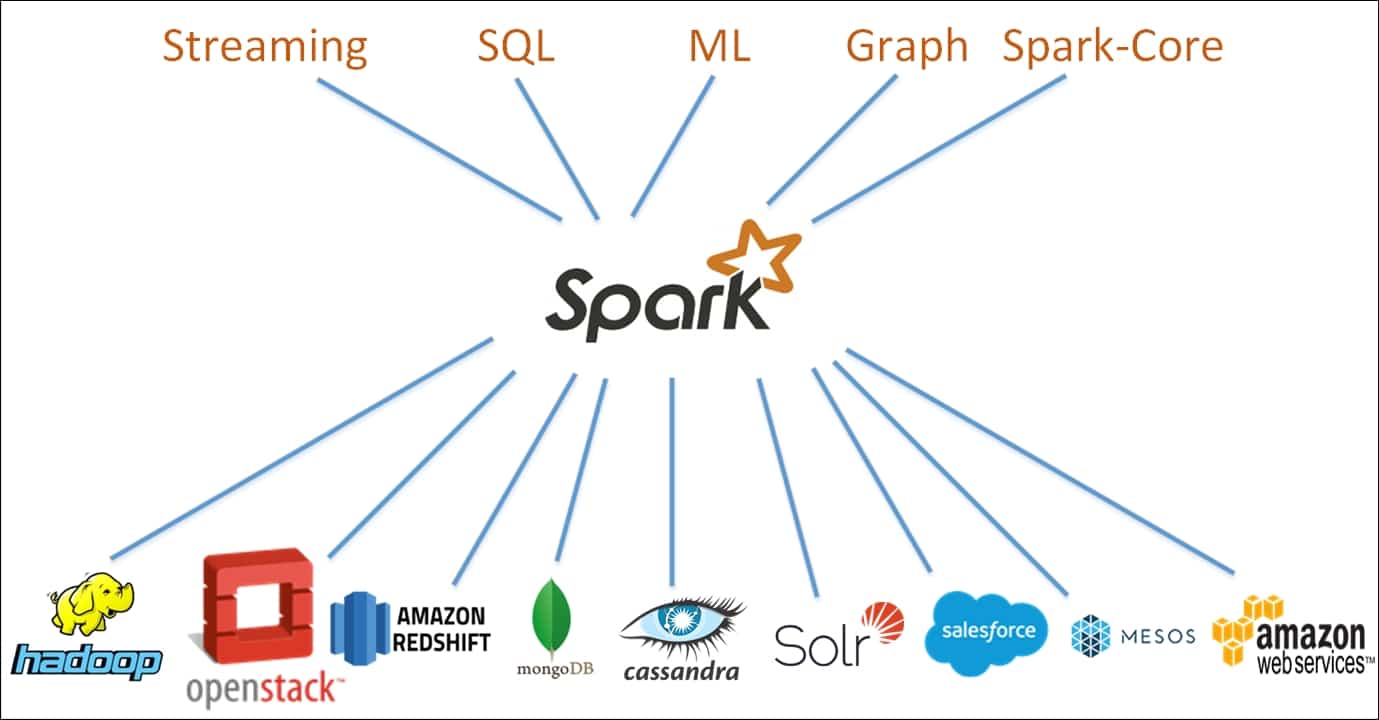
Apache Spark to darmowy framework do obliczeń rozproszonych o otwartym kodzie źródłowym, zaprojektowany w celu umożliwienia prostej i wydajnej analizy danych. Opracowany jako projekt Apache Software Foundation, Spark obsługuje obecnie przetwarzanie danych w pamięci, interaktywne przetwarzanie zapytań, przetwarzanie strumieniowe i algorytmy uczenia maszynowego.
Apache Spark został pierwotnie wydany w 2009 roku w celu zapewnienia analitykom danych i badaczom alternatywy dla powszechnie używanego frameworka MapReduce opracowanego przez Google. Od tego czasu Spark stał się de facto standardem dla ram przetwarzania danych w pamięci w środowisku obliczeń rozproszonych.
Spark jest zbudowany w oparciu o paradygmat obliczeń klastrowych, z węzłem głównym służącym jako kontroler dla całego klastra. Węzły - lub "pracownicy" - w klastrze są odpowiedzialne za odczytywanie i zapisywanie danych ze źródeł zewnętrznych. Architektura Spark składa się z wielu warstw, z których każda została zaprojektowana w celu zwiększenia wydajności i mocy przetwarzania danych. Rdzeniem architektury Spark jest Resilient Distributed Dataset (RDD), rozproszony klaster pamięci, który przechowuje dane w klastrze węzłów.
Spark oferuje szereg funkcji, które sprawiają, że nadaje się do różnych zadań przetwarzania danych. Funkcje te obejmują optymalizację zapytań, odporność na błędy i graficzne interfejsy użytkownika. Ponadto Spark został zaprojektowany z myślą o łatwym skalowaniu do większych klastrów, zapewniając wysoce elastyczną platformę dla programistów. Rusztowanie zapewniane przez framework Apache Spark ułatwia projektowanie zarówno prostych, jak i złożonych aplikacji do analizy danych.
Apache Spark staje się coraz bardziej popularnym narzędziem dla analityków danych pracujących z dużymi zbiorami danych. Ponadto, Spark jest powszechnie wykorzystywany do analizy dużych zbiorów danych w czasie rzeczywistym, uczenia maszynowego i przetwarzania języka naturalnego. Wreszcie, ze względu na swoją skalowalność i solidny zestaw funkcji, Spark jest wykorzystywany do opracowywania różnorodnych aplikacji do analizy predykcyjnej.
Ogólnie rzecz biorąc, Apache Spark to potężny rozproszony framework obliczeniowy do analizy danych i uczenia maszynowego, który szybko staje się platformą dla programistów poszukujących wydajnego i wszechstronnego rozwiązania do swoich projektów analizy danych na dużą skalę.