O Apache Spark é uma estrutura de computação distribuída gratuita e de código aberto projetada para permitir uma análise de dados simples e eficiente. Desenvolvido como um projeto da Apache Software Foundation, o Spark atualmente oferece suporte ao processamento de dados na memória, ao processamento interativo de consultas, ao processamento de fluxos e aos algoritmos de aprendizado de máquina.
O Apache Spark foi lançado inicialmente em 2009 com o objetivo de oferecer aos analistas e pesquisadores de dados uma alternativa à estrutura MapReduce comumente usada, desenvolvida pelo Google. Desde então, o Spark se tornou o padrão de fato para estruturas de processamento de dados na memória no cenário da computação distribuída.
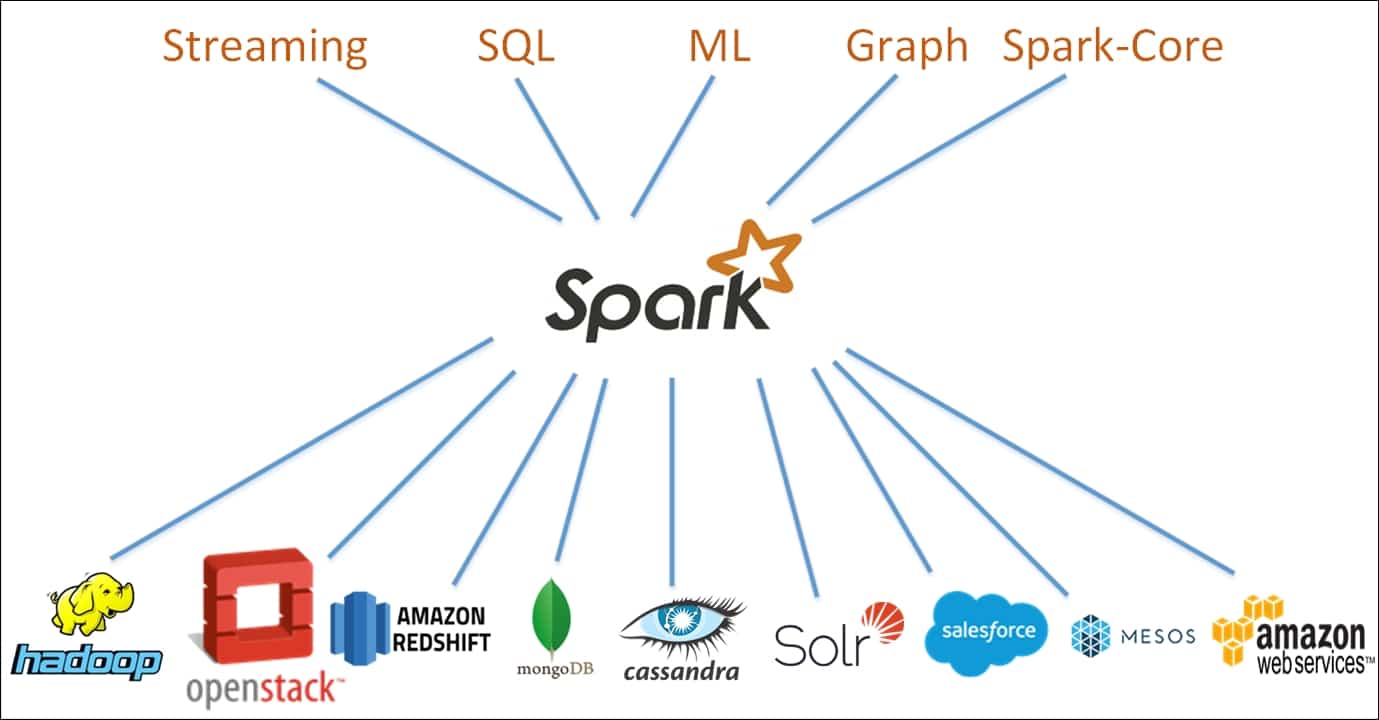
O Spark foi desenvolvido com base em um paradigma de computação em cluster, com um nó mestre atuando como controlador de todo o cluster. Os nós - ou "trabalhadores" - no cluster são responsáveis pela leitura e gravação de dados de fontes externas. A arquitetura do Spark é composta de várias camadas, cada uma delas projetada para tornar o processamento de dados mais eficiente e poderoso. O núcleo da arquitetura do Spark é o Resilient Distributed Dataset (RDD), um cluster de memória distribuída que armazena dados em um cluster de nós.
O Spark oferece uma variedade de recursos que o tornam adequado para uma variedade de tarefas de processamento de dados. Esses recursos incluem otimização de consultas, tolerância a falhas e interfaces gráficas de usuário. Além disso, o Spark foi projetado para ser dimensionado para clusters maiores com facilidade, fornecendo uma estrutura altamente elástica para os desenvolvedores. A estrutura de andaimes fornecida pelo Apache Spark facilita a criação de aplicativos de análise de dados simples e complexos.
O Apache Spark está se tornando cada vez mais popular como uma ferramenta poderosa para cientistas de dados que trabalham com grandes conjuntos de dados. Além disso, o Spark está sendo amplamente usado para análise de Big Data em tempo real, aprendizado de máquina e processamento de linguagem natural. Por fim, devido à sua escalabilidade e ao conjunto robusto de recursos, o Spark está sendo usado para desenvolver uma gama diversificada de aplicativos de análise preditiva.
De modo geral, o Apache Spark é uma poderosa estrutura de computação distribuída para análise de dados e aprendizado de máquina, e está se tornando rapidamente a plataforma de referência para desenvolvedores que buscam uma solução avançada e versátil para seus projetos de análise de dados em grande escala.