Naïeve Bayes (ook bekend als “Bayesiaanse classificatie”) is een algoritme dat wordt gebruikt bij leren onder toezicht en dat vaak wordt gebruikt bij machinaal leren, en specifiek bij gegevensclassificatie. De basisaanname achter het Naive Bayes-algoritme is dat attributen onafhankelijk zijn en geen effect op elkaar hebben.
Het doel van een Naive Bayes-algoritme is om de uitkomst van een bepaalde gebeurtenis te voorspellen, op basis van gegevens die al zijn gezien. Het algoritme zoekt naar patronen in de gegevens om toekomstige gebeurtenissen te voorspellen. Dit type algoritme is nuttig bij het classificeren van gegevens die nog niet zijn gelabeld en waarvoor geen training nodig is.
Naïeve Bayes-algoritmen worden doorgaans gebruikt voor classificatietaken zoals spamdetectie, sentimentanalyse en tekstclassificatie. Het algoritme verdeelt gegevens in categorieën zoals spam of geen spam, positief of negatief, en categorieën zoals deze.
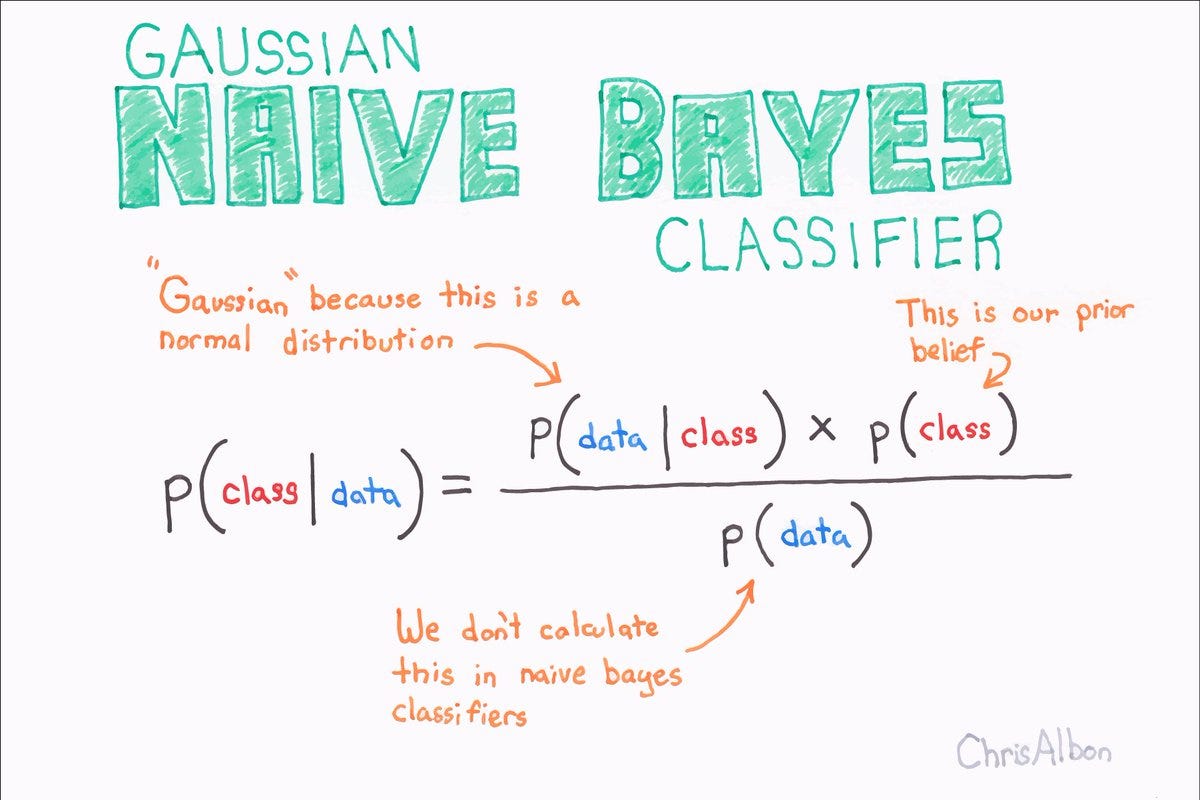
Het Naive Bayes-algoritme is gebaseerd op de stelling van Bayes, die de waarschijnlijkheid vaststelt dat een gebeurtenis plaatsvindt, gegeven enig bewijs. Het Naive Bayes-algoritme berekent voor elke categorie een waarschijnlijkheid op basis van bewijsmateriaal uit de invoergegevens. De categorie met de hoogste waarschijnlijkheid is degene met de meest waarschijnlijke uitkomst.
Om het Naive Bayes-algoritme in code te implementeren, moet de onderzoeker de principes van Bayesiaanse waarschijnlijkheden begrijpen en bekend zijn met de basisprogrammering van Python.
Over het geheel genomen is het Naive Bayes-algoritme een eenvoudig en efficiënt machine learning-algoritme dat vaak wordt gebruikt bij gegevensclassificatie en voorspellingstaken. Het algoritme is eenvoudig te gebruiken en te begrijpen, waardoor het een krachtig hulpmiddel is voor veel taken.