Naive Bayes (noto anche come "Classificazione Bayesiana") è un algoritmo utilizzato nell'apprendimento supervisionato comunemente utilizzato nell'apprendimento automatico e in particolare nella classificazione dei dati. Il presupposto di base dell’algoritmo di Naive Bayes è che gli attributi sono indipendenti e non hanno alcun effetto gli uni sugli altri.
L’obiettivo di un algoritmo di Naive Bayes è prevedere l’esito di un qualche tipo di evento, dati i dati già osservati. L'algoritmo cerca modelli nei dati per prevedere eventi futuri. Questo tipo di algoritmo è utile per classificare i dati non ancora etichettati e non richiede formazione.
Gli algoritmi Naive Bayes vengono generalmente utilizzati per attività di classificazione come il rilevamento dello spam, l'analisi del sentiment e la classificazione del testo. L'algoritmo suddivide i dati in categorie come spam o non spam, positivo o negativo e categorie come queste.
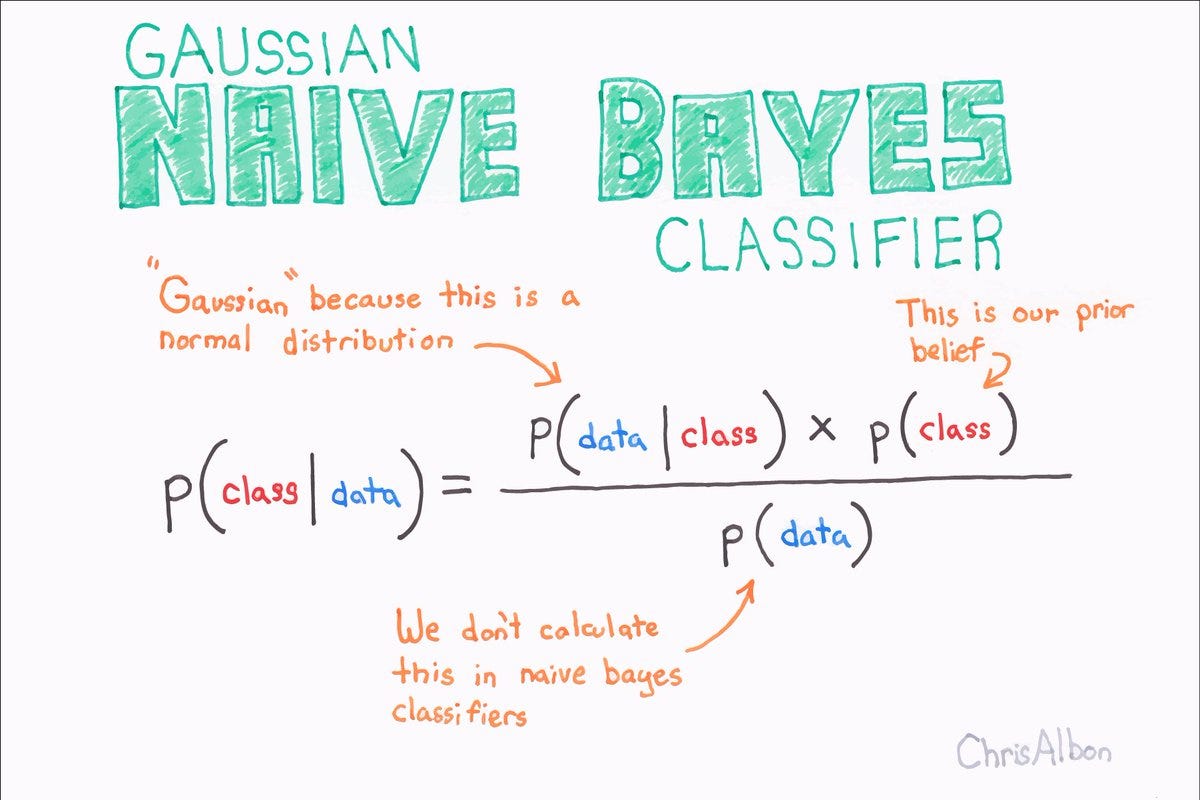
L'algoritmo Naive Bayes si basa sul teorema di Bayes, che stabilisce la probabilità che un evento si verifichi in presenza di un'evidenza. L'algoritmo Naive Bayes calcola una probabilità per ogni categoria, utilizzando le prove dei dati in ingresso. La categoria con la probabilità più alta è quella con il risultato più probabile.
Per implementare l'algoritmo Naive Bayes nel codice, il ricercatore deve comprendere i principi delle probabilità bayesiane e avere familiarità con la programmazione di base di Python.
Nel complesso, l'algoritmo di Naive Bayes è un algoritmo di apprendimento automatico semplice ed efficiente, comunemente utilizzato per la classificazione e la previsione dei dati. L'algoritmo è semplice da usare e da capire, il che lo rende uno strumento potente per molti compiti.