Naive Bayes (còn được gọi là “Phân loại Bayes”) là một thuật toán được sử dụng trong học tập có giám sát, thường được sử dụng trong học máy và đặc biệt là trong phân loại dữ liệu. Giả định cơ bản đằng sau thuật toán Naive Bayes là các thuộc tính độc lập và không ảnh hưởng lẫn nhau.
Mục tiêu của thuật toán Naive Bayes là dự đoán kết quả của một số loại sự kiện, dựa trên dữ liệu đã được nhìn thấy. Thuật toán tìm kiếm các mẫu trong dữ liệu để dự đoán các sự kiện trong tương lai. Loại thuật toán này rất hữu ích trong việc phân loại dữ liệu chưa được gắn nhãn và không cần đào tạo.
Thuật toán Naive Bayes thường được sử dụng cho các nhiệm vụ phân loại như phát hiện thư rác, phân tích cảm xúc và phân loại văn bản. Thuật toán chia dữ liệu thành các danh mục như spam hoặc không spam, tích cực hoặc tiêu cực và các danh mục như thế này.
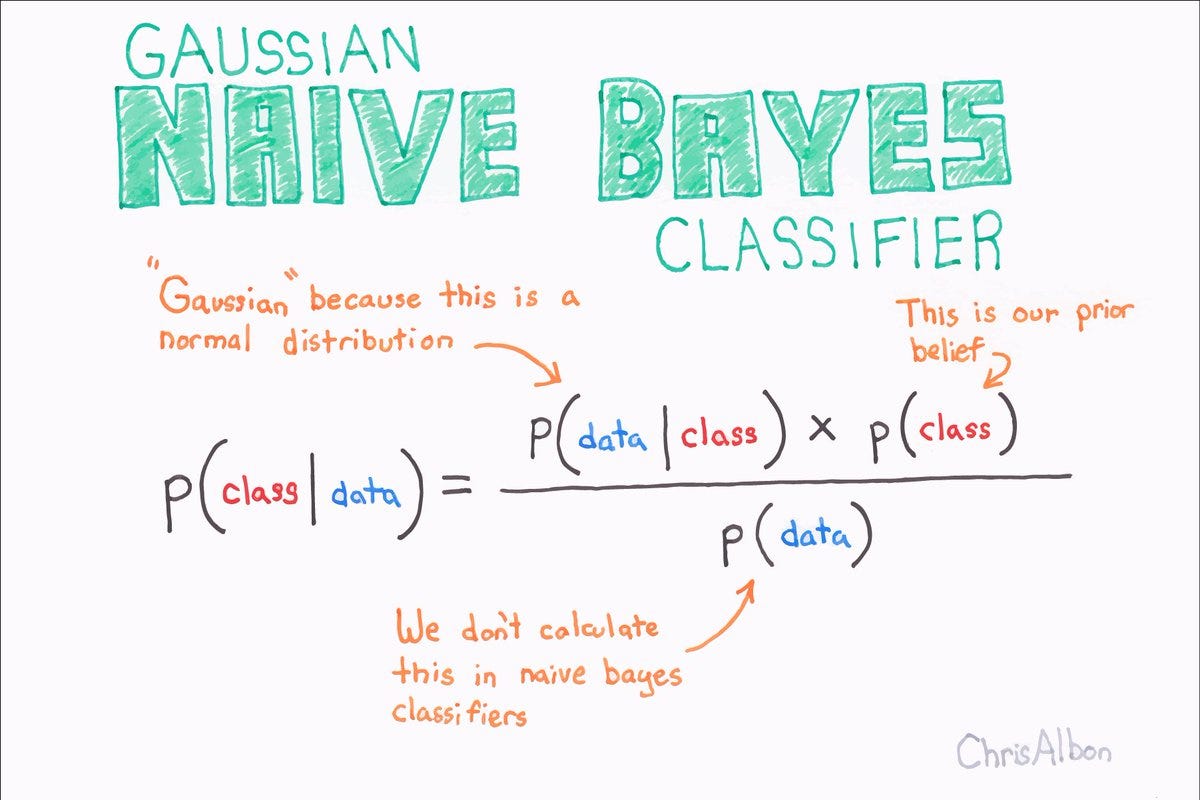
Thuật toán Naive Bayes dựa trên định lý Bayes, trong đó thiết lập xác suất xảy ra một sự kiện dựa trên một số bằng chứng. Thuật toán Naive Bayes tính toán xác suất cho từng danh mục, sử dụng bằng chứng từ dữ liệu đầu vào. Loại có xác suất cao nhất là loại có kết quả có thể xảy ra nhất.
Để triển khai thuật toán Naive Bayes trong mã, nhà nghiên cứu phải hiểu các nguyên tắc xác suất Bayes và làm quen với lập trình Python cơ bản.
Nhìn chung, thuật toán Naive Bayes là một thuật toán học máy đơn giản và hiệu quả, thường được sử dụng trong các nhiệm vụ dự đoán và phân loại dữ liệu. Thuật toán rất dễ sử dụng và dễ hiểu, khiến nó trở thành một công cụ mạnh mẽ cho nhiều tác vụ.