O Naive Bayes (também conhecido como "Classificação Bayesiana") é um algoritmo usado no aprendizado supervisionado que é comumente usado no aprendizado de máquina e, especificamente, na classificação de dados. A suposição básica por trás do algoritmo Naive Bayes é que os atributos são independentes e não têm efeito uns sobre os outros.
O objetivo de um algoritmo Naive Bayes é prever o resultado de algum tipo de evento, com base em dados que já foram vistos. O algoritmo procura padrões nos dados para prever eventos futuros. Esse tipo de algoritmo é útil na classificação de dados que ainda não foram rotulados e não requer treinamento.
Os algoritmos Naive Bayes são normalmente usados para tarefas de classificação, como detecção de spam, análise de sentimentos e classificação de texto. O algoritmo divide os dados em categorias, como spam ou não spam, positivo ou negativo, e categorias como essas.
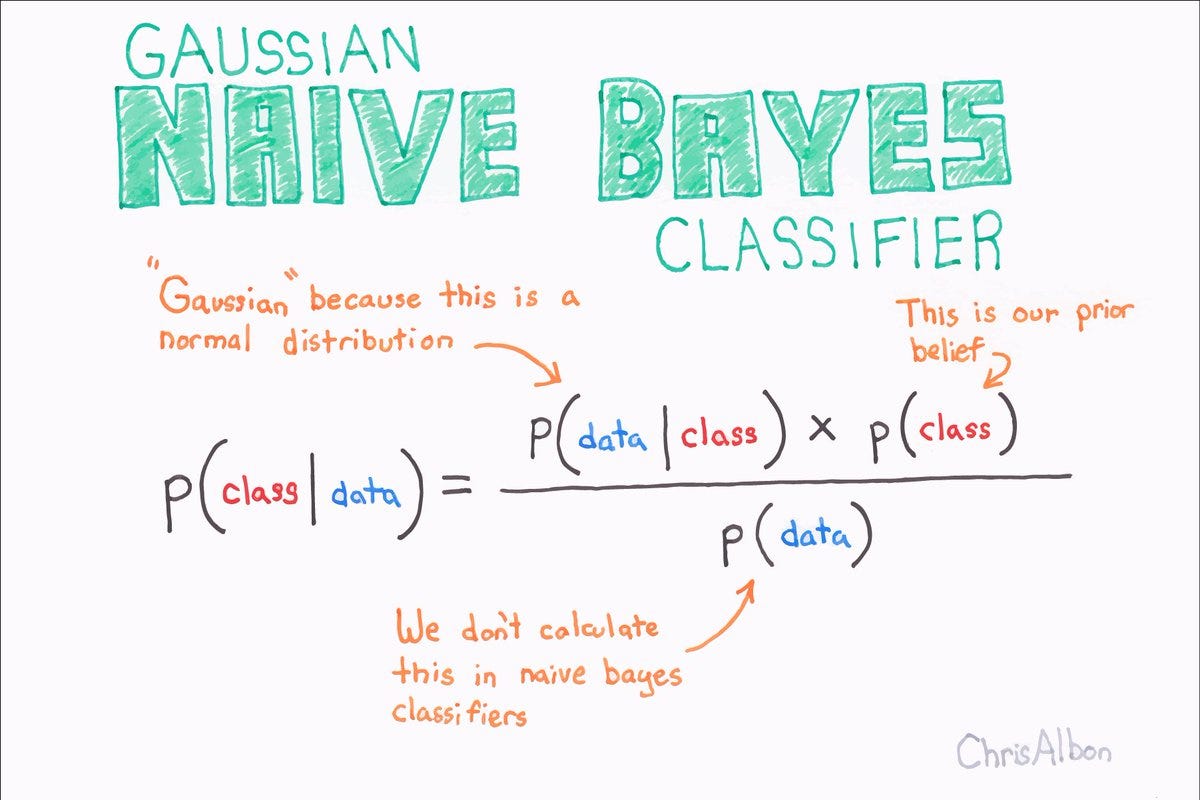
O algoritmo Naive Bayes baseia-se no teorema de Bayes, que estabelece a probabilidade de ocorrência de um evento com base em algumas evidências. O algoritmo Naive Bayes calcula uma probabilidade para cada categoria, usando evidências dos dados de entrada. A categoria com a maior probabilidade é a que tem o resultado mais provável.
Para implementar o algoritmo Naive Bayes em código, o pesquisador deve entender os princípios das probabilidades bayesianas e estar familiarizado com a programação básica em Python.
Em geral, o algoritmo Naive Bayes é um algoritmo de aprendizado de máquina simples e eficiente, comumente usado em tarefas de classificação e previsão de dados. O algoritmo é simples de usar e entender, o que o torna uma ferramenta poderosa para muitas tarefas.