Naive Bayes (también conocido como "clasificación bayesiana") es un algoritmo utilizado en el aprendizaje supervisado que suele emplearse en el aprendizaje automático y, concretamente, en la clasificación de datos. La hipótesis básica del algoritmo Naive Bayes es que los atributos son independientes y no se influyen entre sí.
El objetivo de un algoritmo Naive Bayes es predecir el resultado de algún tipo de evento, dados los datos que ya se han visto. El algoritmo busca patrones en los datos para predecir sucesos futuros. Este tipo de algoritmo es útil para clasificar datos que aún no están etiquetados y no requiere entrenamiento.
Los algoritmos Naive Bayes se utilizan normalmente para tareas de clasificación como la detección de spam, el análisis de sentimientos y la clasificación de textos. El algoritmo divide los datos en categorías como, spam o no spam, positivo o negativo, y categorías como estas.
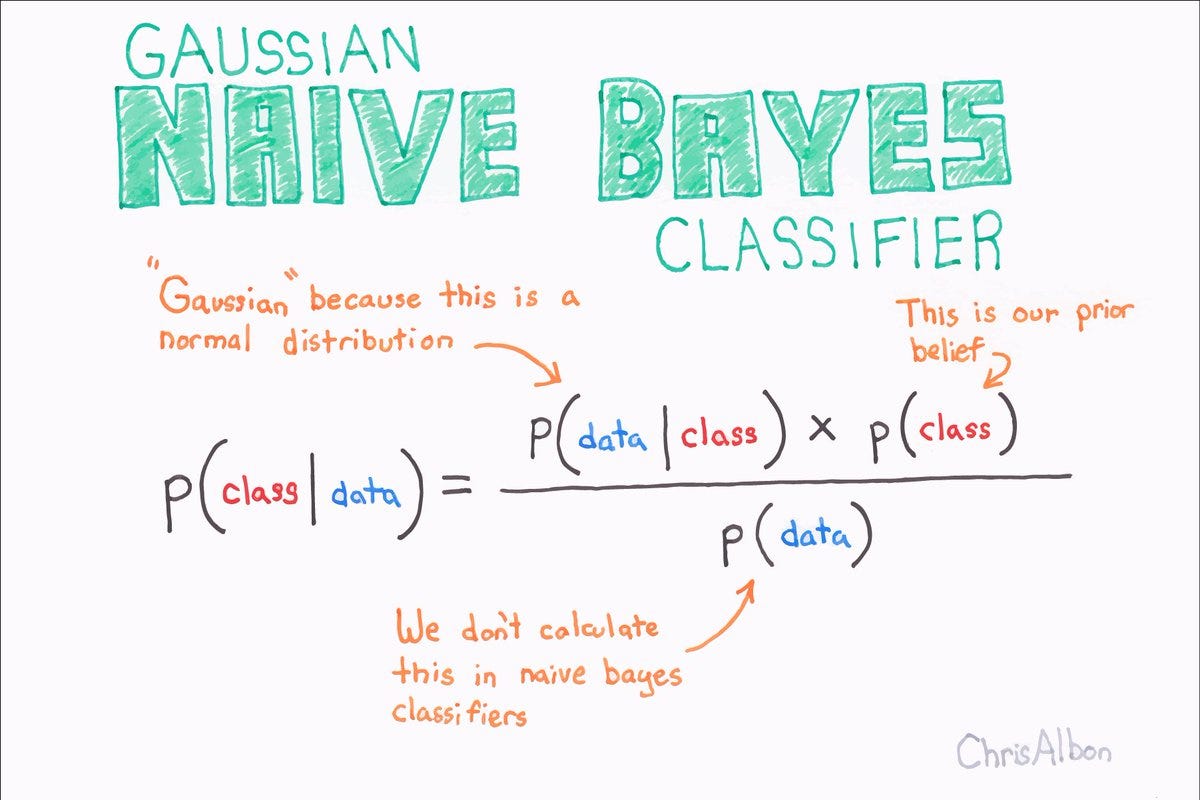
El algoritmo Naive Bayes se basa en el teorema de Bayes, que establece la probabilidad de que ocurra un suceso dadas algunas pruebas. El algoritmo Naive Bayes calcula una probabilidad para cada categoría, utilizando las pruebas de los datos de entrada. La categoría con la probabilidad más alta es la que tiene el resultado más probable.
Para implementar el algoritmo Naive Bayes en código, el investigador debe comprender los principios de las probabilidades bayesianas y estar familiarizado con la programación básica en Python.
En general, el algoritmo Naive Bayes es un algoritmo de aprendizaje automático sencillo y eficaz que se utiliza habitualmente en tareas de clasificación y predicción de datos. El algoritmo es fácil de usar y entender, lo que lo convierte en una herramienta potente para muchas tareas.