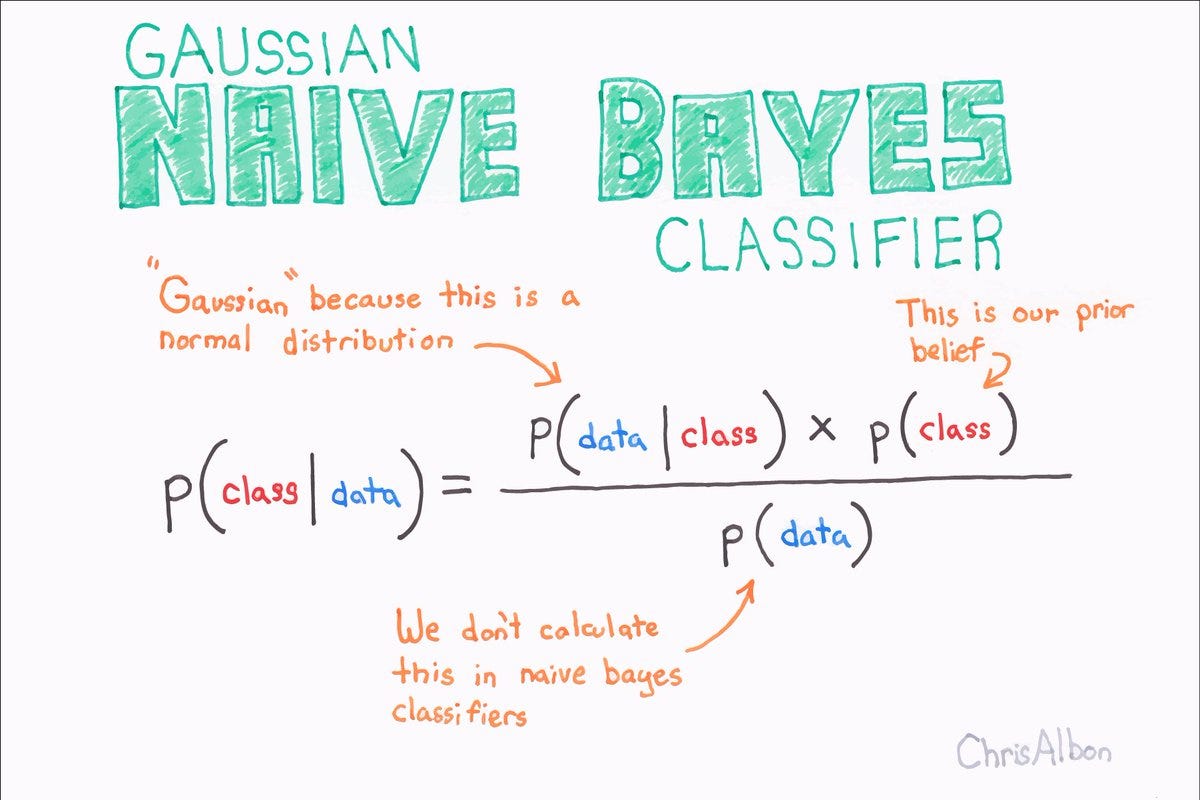
Naive Bayes (also known as “Bayesian Classification”) is an algorithm used in supervised learning which is commonly used in machine learning, and specifically in data classification. The basic assumption behind the Naive Bayes algorithm is that attributes are independent and have no effect on each other.
The goal of a Naive Bayes algorithm is to predict the outcome of some kind of event, given data that has already been seen. The algorithm looks for patterns in the data to predict future events. This type of algorithm is helpful in classifying data that is not labeled yet and requires no training.
Naive Bayes algorithms are typically used for classification tasks such as spam detection, sentiment analysis, and text classification. The algorithm splits data into categories such as, spam or not spam, positive or negative, and categories like these.
The Naive Bayes algorithm is based on the Bayes’ theorem, which establishes the probability of an event occurring given some evidence. The Naive Bayes algorithm calculates a probability for each category, using evidence from the input data. The category with the highest probability is the one with the most probable outcome.
To implement the Naive Bayes algorithm in code, the researcher must understand the principles of Bayesian probabilities and be familiar with basic Python programming.
Overall, the Naive Bayes algorithm is a simple and efficient machine learning algorithm which is commonly used in data classification and prediction tasks. The algorithm is simple to use and understand, making it a powerful tool for many tasks.