MapReduce は、分散コンピューティング タスクに使用されるプログラミング モデルです。これは、複雑な計算問題をより小さく、より管理しやすい部分に分割することで解決する分割統治アプローチに基づいています。 MapReduce モデルは主に大規模なデータ セットで使用され、通常は計算能力を汎用サーバーのクラスターに依存します。
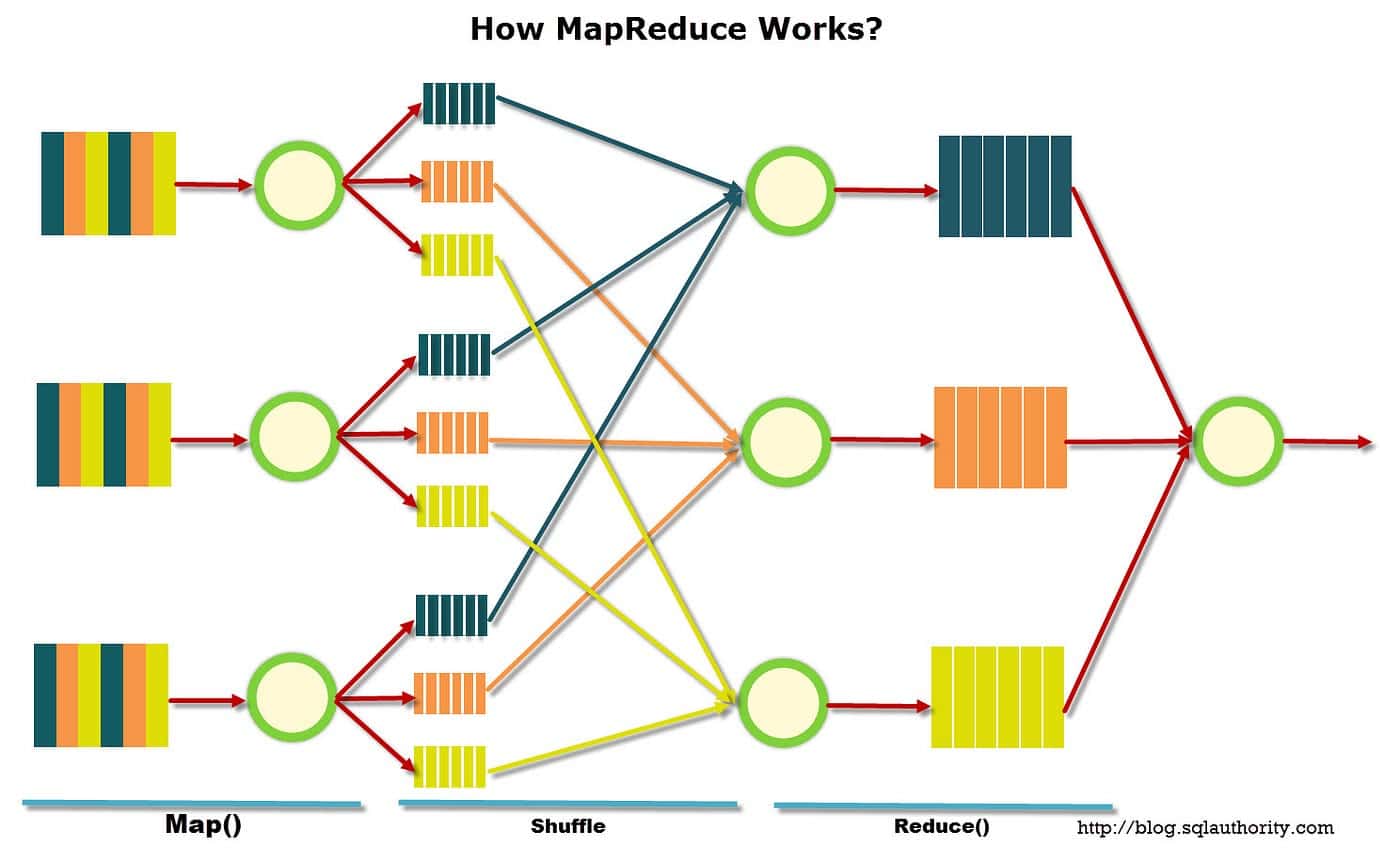
MapReduceは、2004年にGoogleの研究者たちによって初めて導入され、以来、データ分析と処理のための一般的なツールとなった。このモデルでは、マップとリデュースの2つの段階がある。
マップフェーズでは、データが「スプリット」と呼ばれるチャンクに分割されます。各分割は、データを処理してキーと値のペアのセットを出力するマッパーに割り当てられます。次に、キーと値のペアがリデュース フェーズに送られ、そこで並べ替えられて 1 つの出力に集約されます。
MapReduce モデルは、データ マイニング、機械学習、自然言語処理などの多くのタスクに役立ちます。 Web ログやサーバー ログなどの大量のデータを分析し、大規模なデータ セットを迅速に処理するために最もよく使用されます。
MapReduce は、Java、Python、C# などの多くの一般的なプログラミング言語に統合されており、Hadoop や Apache Spark などのいくつかの一般的なプラットフォームでサポートされています。その結果、これはデータ処理と分析のための一般的なツールとなり、大規模なデータセットから価値を引き出すためにさまざまな組織で使用されています。