MapReduce는 분산 컴퓨팅 작업에 사용되는 프로그래밍 모델입니다. 이는 복잡한 계산 문제를 더 작고 관리하기 쉬운 조각으로 나누어 해결하는 분할 정복 접근 방식을 기반으로 합니다. MapReduce 모델은 주로 대규모 데이터 세트에 사용되며 일반적으로 컴퓨팅 성능을 위해 상용 서버 클러스터에 의존합니다.
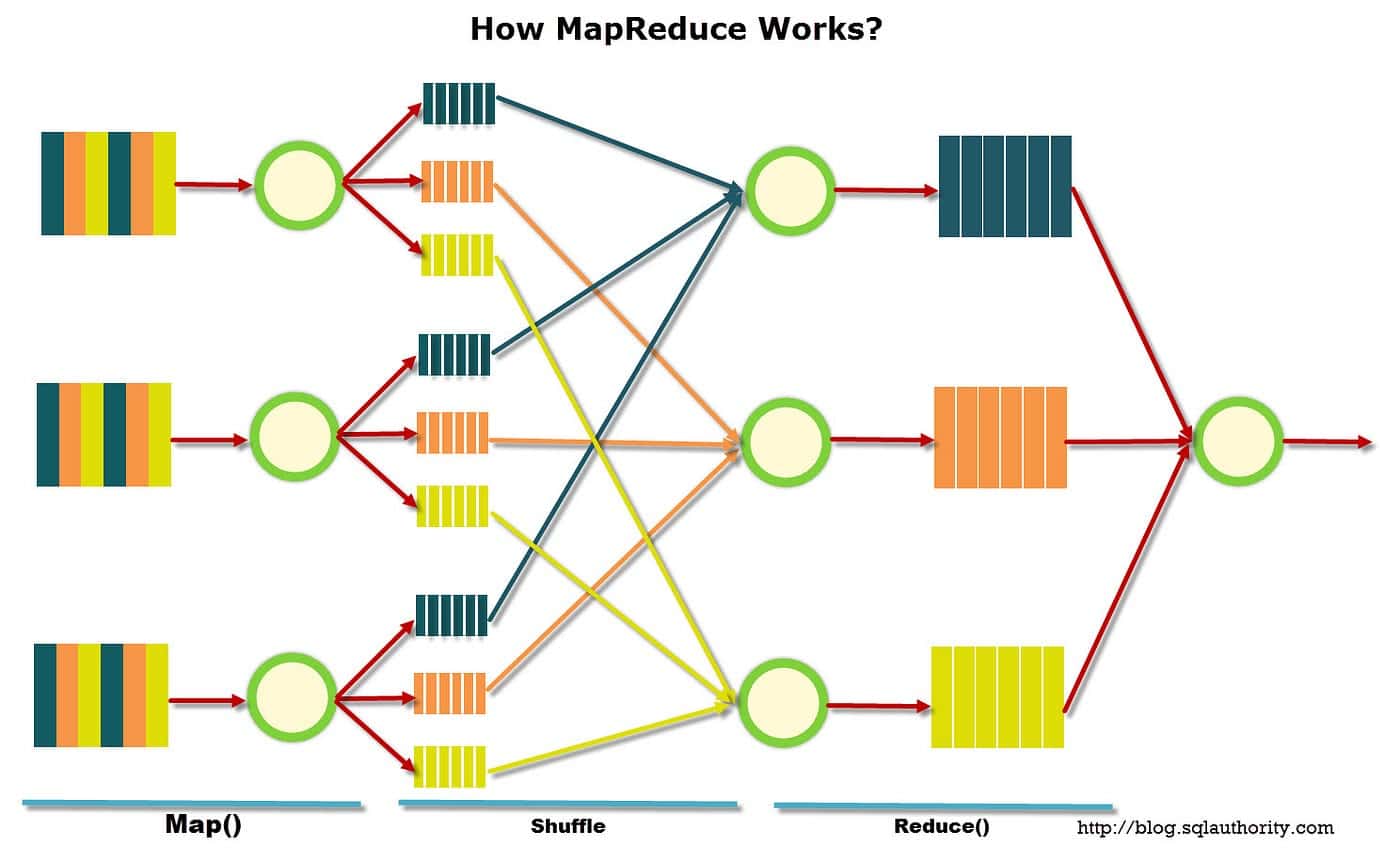
MapReduce는 2004년 Google 연구원에 의해 처음 소개된 이후 데이터 분석 및 처리를 위한 인기 있는 도구가 되었습니다. 이 모델에는 맵 단계와 축소 단계라는 두 가지 별개의 단계가 있습니다.
맵 단계에서 데이터는 "분할"이라는 덩어리로 분할됩니다. 각 분할은 데이터를 처리하고 키-값 쌍 집합을 출력하는 매퍼에 할당됩니다. 그런 다음 키-값 쌍은 감소 단계로 전달되어 정렬되고 단일 출력으로 집계됩니다.
MapReduce 모델은 데이터 마이닝, 기계 학습, 자연어 처리를 포함한 많은 작업에 유용합니다. 웹 로그, 서버 로그 등 대용량 데이터를 분석하고 대용량 데이터 세트를 빠르게 처리하는 데 가장 많이 사용됩니다.
MapReduce는 Java, Python 및 C#와 같은 널리 사용되는 여러 프로그래밍 언어에 통합되었으며 Hadoop 및 Apache Spark와 같은 여러 널리 사용되는 플랫폼에서 지원됩니다. 결과적으로 이는 데이터 처리 및 분석을 위한 일반적인 도구가 되었으며 다양한 조직에서 대규모 데이터 세트에서 가치를 도출하는 데 사용됩니다.