MapReduce é um modelo de programação usado para tarefas de computação distribuída. Baseia-se em uma abordagem de dividir e conquistar para resolver problemas computacionais complexos, dividindo-os em partes menores e mais gerenciáveis. O modelo MapReduce é usado principalmente em grandes conjuntos de dados e geralmente depende de um cluster de servidores comuns para poder computacional.
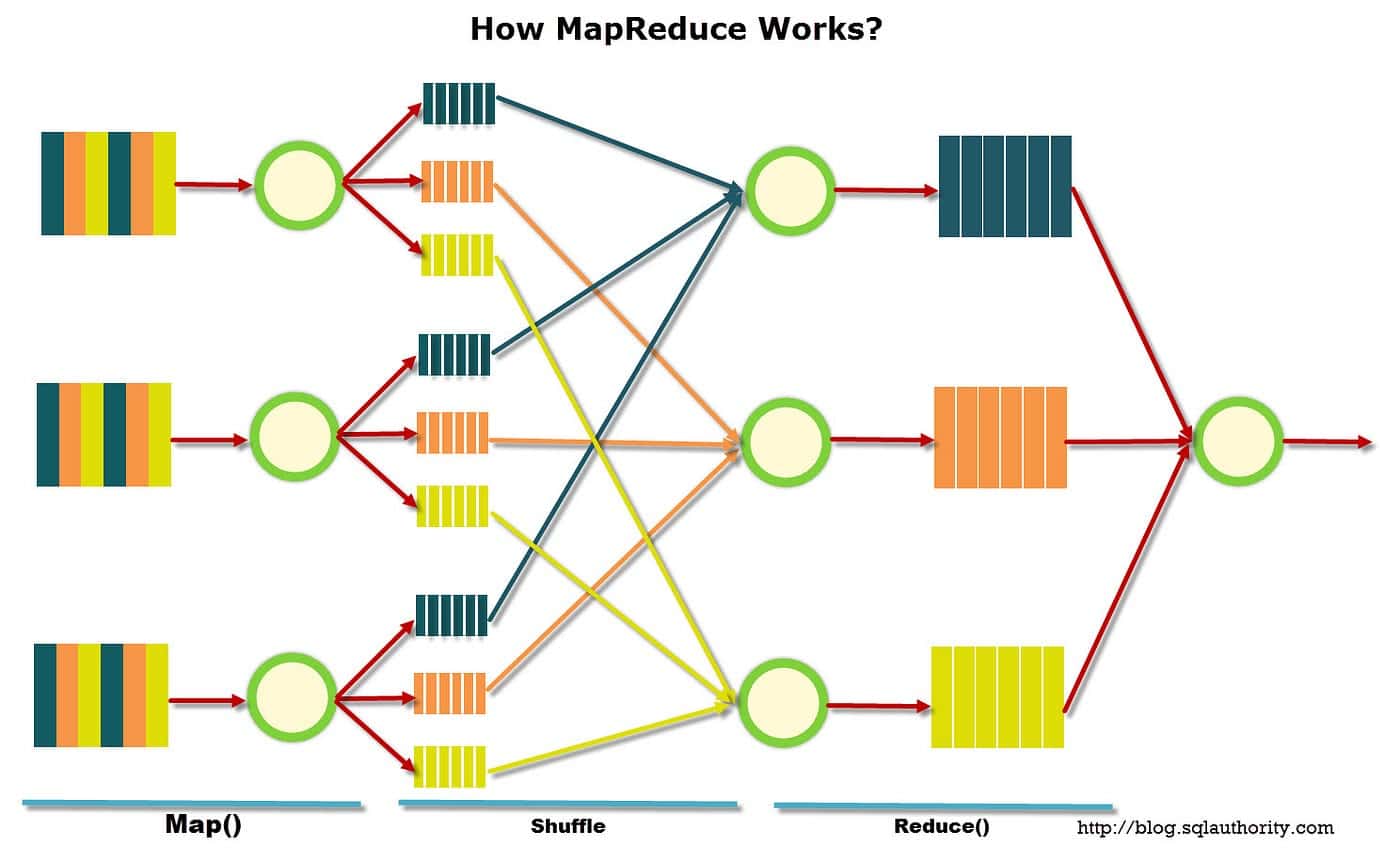
O MapReduce foi introduzido pela primeira vez por pesquisadores do Google em 2004 e desde então se tornou uma ferramenta popular para análise e processamento de dados. Neste modelo, existem duas fases distintas – as fases de mapeamento e redução.
Na fase de mapa, os dados são divididos em pedaços chamados “divisões”. Cada divisão é atribuída a um mapeador que processa os dados e gera um conjunto de pares de valores-chave. Os pares de valores-chave são então alimentados na fase de redução, onde são classificados e agregados em uma única saída.
O modelo MapReduce é benéfico para muitas tarefas, incluindo mineração de dados, aprendizado de máquina e processamento de linguagem natural. É mais frequentemente usado para analisar grandes quantidades de dados, como logs da web e logs de servidor, e para processar grandes conjuntos de dados rapidamente.
MapReduce foi integrado a muitas linguagens de programação populares, como Java, Python e C#, e é compatível com diversas plataformas populares, como Hadoop e Apache Spark. Como resultado, tornou-se uma ferramenta comum para processamento e análise de dados e está sendo usada por uma ampla variedade de organizações para ajudá-las a obter valor de grandes conjuntos de dados.