MapReduce je programovací model používaný pro distribuované výpočetní úlohy. Je založen na přístupu rozděl a panuj k řešení složitých výpočetních problémů jejich rozdělením na menší, lépe zvládnutelné části. Model MapReduce se primárně používá na velkých souborech dat a obvykle se spoléhá na cluster komoditních serverů pro výpočetní výkon.
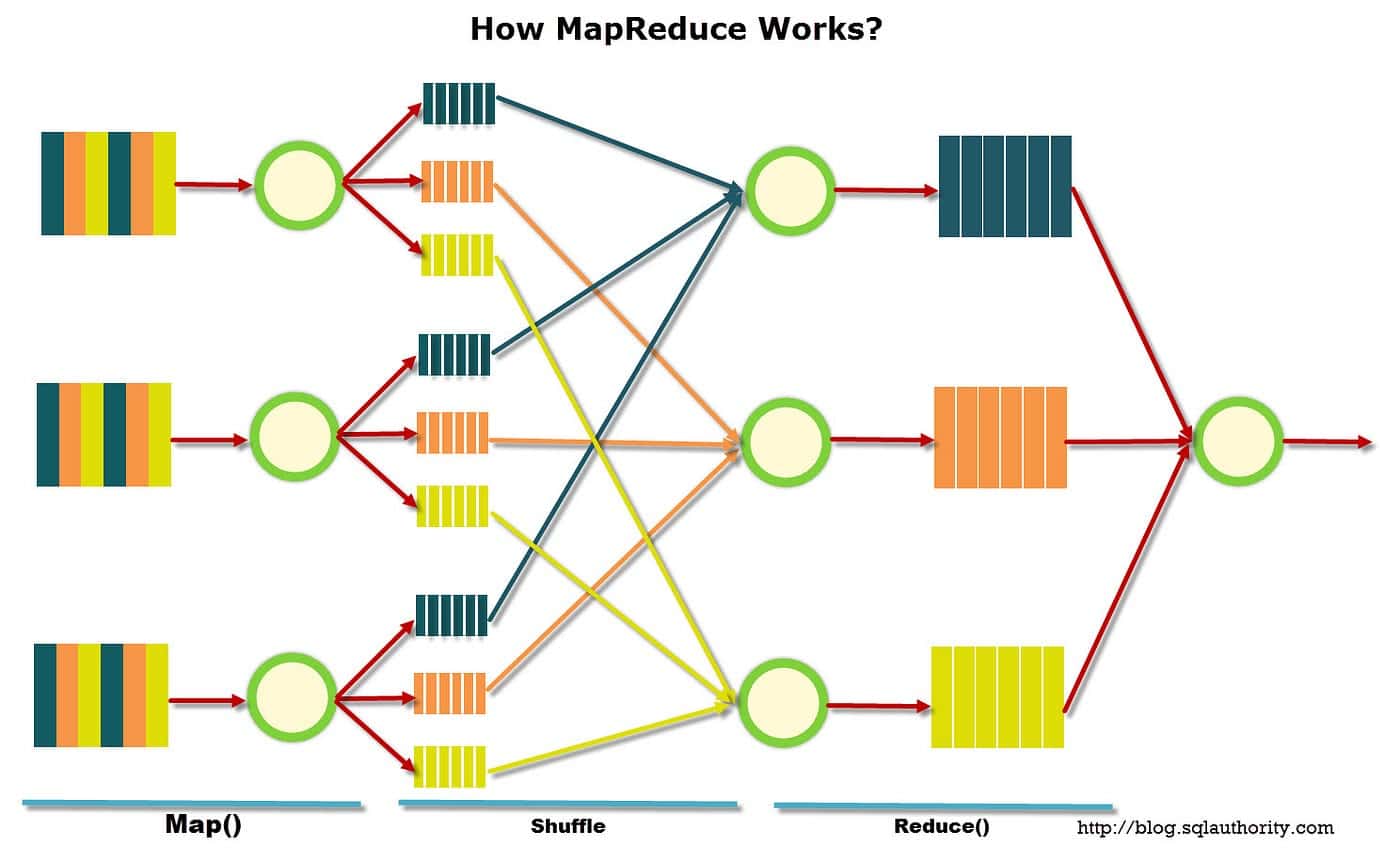
MapReduce byl poprvé představen výzkumníky Google v roce 2004 a od té doby se stal oblíbeným nástrojem pro analýzu a zpracování dat. V tomto modelu existují dvě odlišné fáze – fáze mapy a fáze redukce.
Ve fázi mapy jsou data rozdělena do částí nazývaných „rozdělení“. Každé rozdělení je přiřazeno mapovači, který zpracovává data a vydává sadu párů klíč–hodnota. Páry klíč–hodnota jsou pak přiváděny do fáze redukce, kde jsou tříděny a agregovány do jediného výstupu.
Model MapReduce je výhodný pro mnoho úkolů, včetně dolování dat, strojového učení a zpracování přirozeného jazyka. Nejčastěji se používá k analýze velkého množství dat, jako jsou webové protokoly a protokoly serveru, ak rychlému zpracování velkých souborů dat.
MapReduce byl integrován do mnoha oblíbených programovacích jazyků, jako je Java, Python a C#, a je podporován několika populárními platformami, jako je Hadoop a Apache Spark. V důsledku toho se stal běžným nástrojem pro zpracování a analýzu dat a je používán širokou škálou organizací, aby jim pomohl odvodit hodnotu z velkých souborů dat.