MapReduce is a programming model used for distributed computing tasks. It is based on a divide-and-conquer approach to solving complex computational problems by breaking them down into smaller, more manageable pieces. The MapReduce model is primarily used on large data sets, and usually relies on a cluster of commodity servers for computational power.
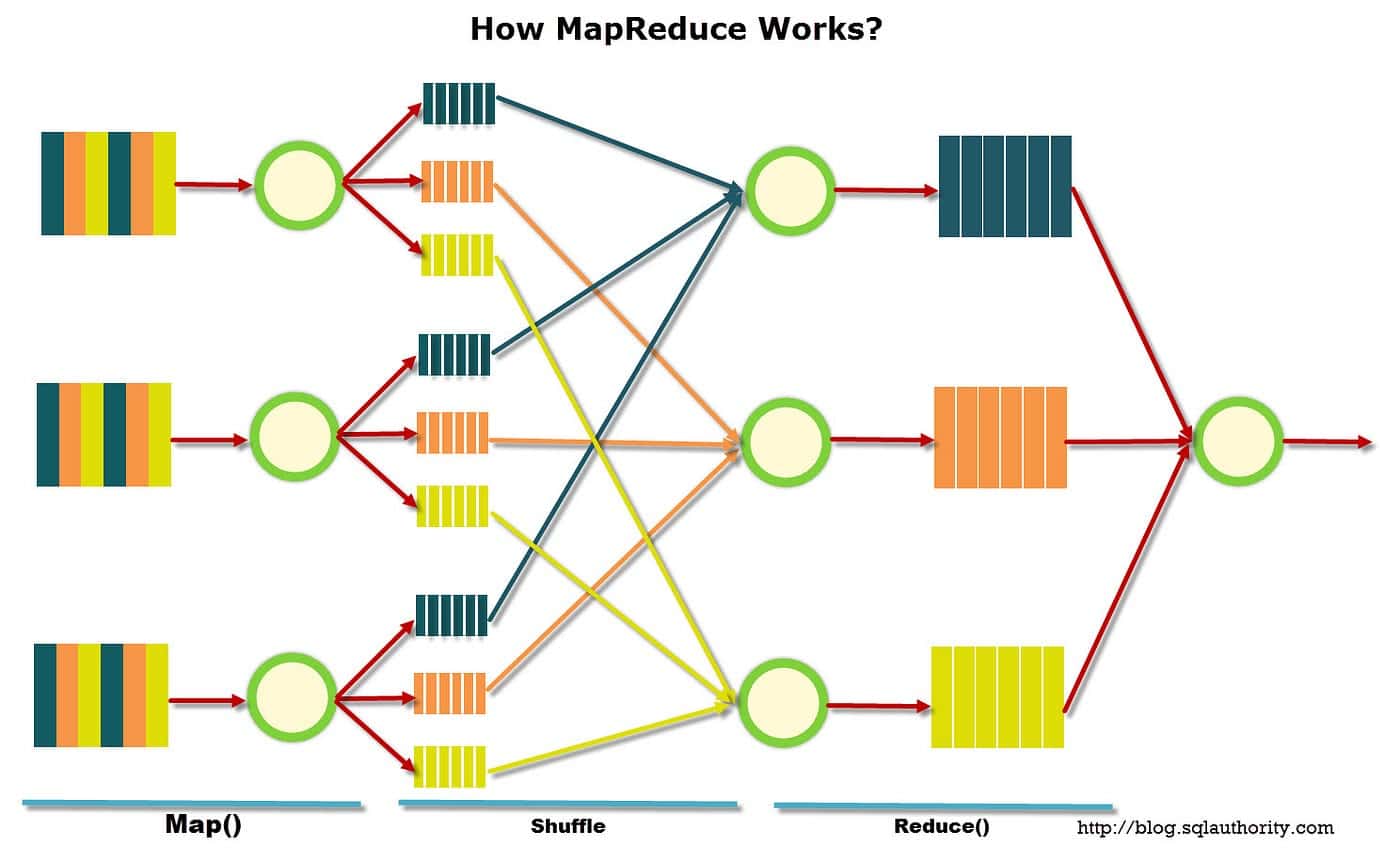
MapReduce was first introduced by Google researchers in 2004, and it has since become a popular tool for data analysis and processing. In this model, there are two distinct stages – the map and reduce phases.
In the map phase, data is split up into chunks called “splits”. Each split is assigned to a mapper that processes the data and outputs a set of key-value pairs. The key-value pairs are then fed into the reduce phase, where they are sorted and aggregated into a single output.
The MapReduce model is beneficial for many tasks, including data mining, machine learning, and natural language processing. It is most often used to analyze large amounts of data, such as web logs and server logs, and to process large data sets quickly.
MapReduce has been integrated into many popular programming languages, such as Java, Python, and C#, and it is supported by several popular platforms, like Hadoop and Apache Spark. As a result, it has become a common tool for data processing and analysis, and is being used by a wide variety of organizations to help them derive value from large data sets.