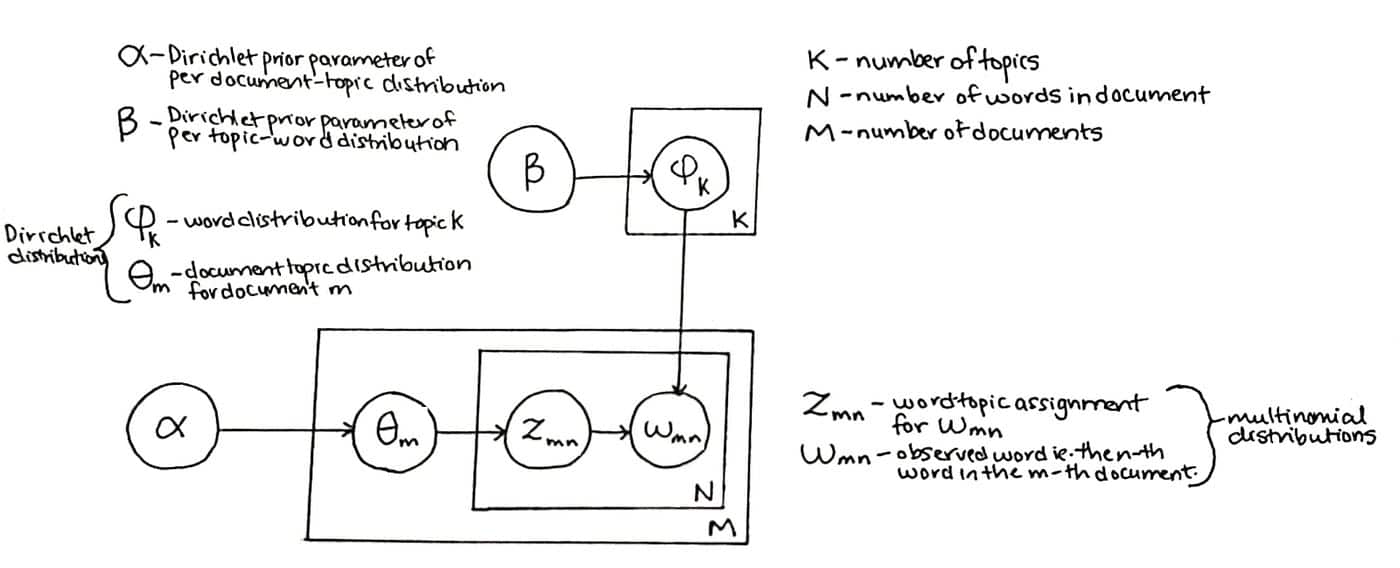
LDA(Latent Dirichlet Allocation)とは、与えられた文書集合に関連するトピックを推定する統計モデルの一種で、文書集合内の文書が事前に定義された集合からのトピックの集まりであるという仮定に基づいている。例えば、プログラミング言語に関する文書は、構文、デバッグ、ライブラリ、データ型などのトピックで構成される。
潜在ディリクレ割り当て(Latent Dirichlet Allocation)は、自然言語処理で使用される教師なし機械学習アルゴリズムで、大規模な文書コーパスに存在する隠れたトピックを発見する。各文書をトピックのセットに割り当て、生成確率モデルを使用して、文書内の特定の単語が特定のトピックに属する確率を決定する。
このアルゴリズムでは、トピックの数と各トピックにおける単語の分布という2つのパラメータを使用する。このモデルは、すべての文書で共有されるトピックの固定セット(「事前分布」と呼ばれる)が存在すると仮定し、各文書についてそれらのトピックの分布を探索する。潜在ディリクレ配置は、電子商取引や電子メールマーケティングアプリケーションの文書など、大規模なテキストコーパスのモデル化に成功した。
LDAは、文書のトピックを決定したり、文書内の各トピックの相対的な重要度を測定するために使用できる。また、どの文書が同じトピックについて議論しているかを特定したり、類似した文書をクラスタリングしたりするのにも使用できる。さらに、ユーザーがすでに興味を持っているトピックに基づいて、追加コンテンツをユーザーに推薦するために使用することもできる。
潜在的ディリクレ割り当て(Latent Dirichlet Allocation)は、自然言語処理の領域における重要なツールであり、テキスト分類、トピックモデリング、文書クラスタリングなどのアプリケーションでますます使用されるようになっている。大規模な文書集合を効率的に分析し、それらの文書のトピックを理解・解釈するために使用することができる。