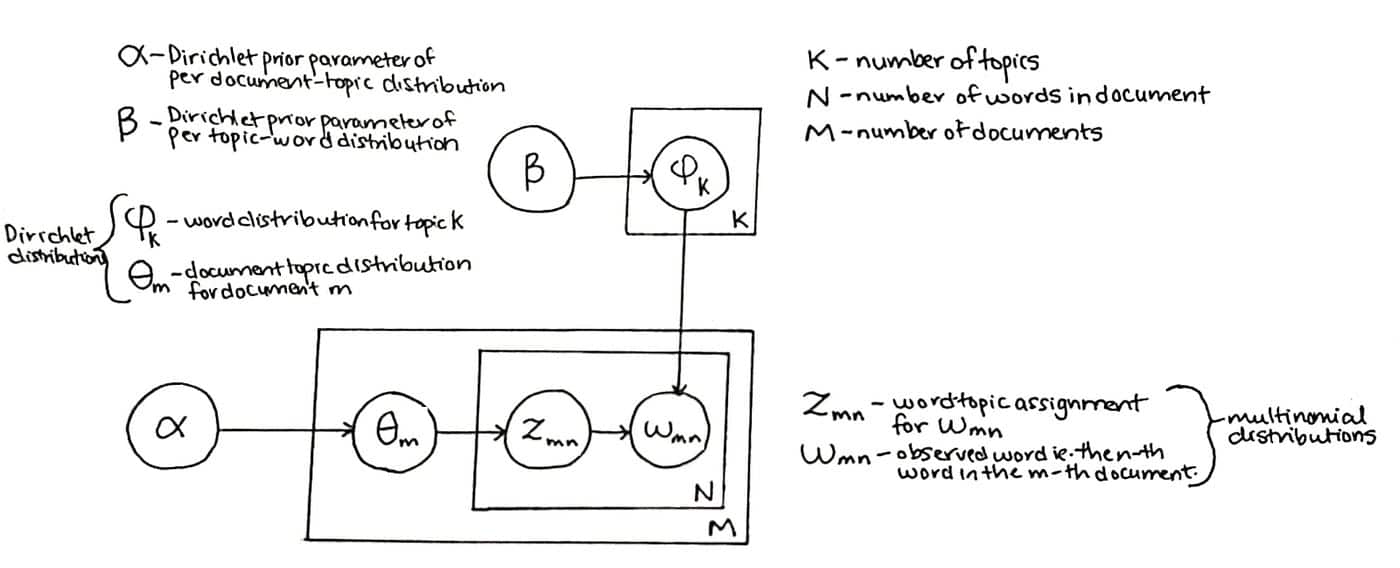
Latentne Dirichleti eraldamine (LDA) on statistilise mudeli tüüp, mis hindab antud dokumendikomplektiga seotud teemasid, lähtudes eeldusest, et komplektis olevad dokumendid on eelmääratletud komplekti teemade kogumid. Näiteks võib programmeerimiskeelt käsitlev dokument koosneda sellistest teemadest nagu süntaks, silumine, teegid ja andmetüübid.
Latent Dirichlet Allocation on järelevalveta masinõppe algoritm, mida kasutatakse loomulikus keele töötlemises, et paljastada peidetud teemad, mis esinevad suures dokumendikorpuses. See toimib, määrates iga dokumendi teemade kogumile ja seejärel kasutab generatiivset tõenäosusmudelit, et määrata kindlaks tõenäosus, et teatud sõna dokumendis kuulub teatud teemasse.
Algoritm kasutab kahte parameetrit – teemade arvu ja sõnade jaotust igas teemas. Mudel eeldab, et on olemas kindel teemade kogum (nn "eelnev"), mida jagavad kõik dokumendid, ja iga dokumendi jaoks otsib see nende teemade jaotusi. Latent Dirichlet Allocation on edukalt rakendatud suurte tekstikorpuste, näiteks e-kaubanduse ja e-turunduse rakenduste dokumentide modelleerimiseks.
LDA abil saab määrata dokumentide teemasid ja mõõta iga teema suhtelist tähtsust dokumendis. Seda saab kasutada ka selleks, et tuvastada, millised dokumendid käsitlevad samu teemasid, või koondada sarnaseid dokumente. Lisaks saab selle abil soovitada kasutajale lisasisu juba teda huvitavate teemade põhjal.
Latentne Dirichleti eraldamine on loomuliku keele töötlemise valdkonnas oluline tööriist ja seda kasutatakse üha enam sellistes rakendustes nagu teksti klassifitseerimine, teemade modelleerimine ja dokumentide rühmitamine. Seda saab kasutada suurte dokumendikogude tõhusaks analüüsimiseks ning nende dokumentide teemade mõistmiseks ja tõlgendamiseks.