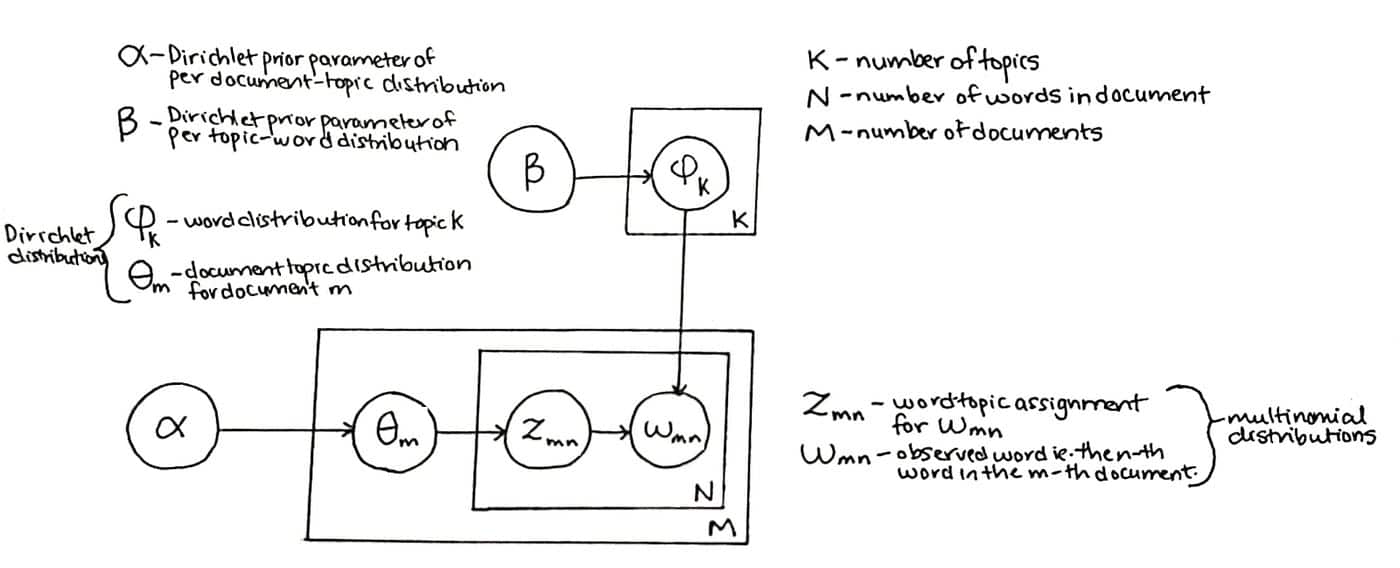
लेटेंट डिरिचलेट आवंटन (एलडीए) एक प्रकार का सांख्यिकीय मॉडल है जो किसी दिए गए दस्तावेज़ सेट से जुड़े विषयों का अनुमान लगाता है, इस धारणा के आधार पर कि सेट में दस्तावेज़ पूर्वनिर्धारित सेट से विषयों का संग्रह हैं। उदाहरण के लिए, प्रोग्रामिंग भाषा के बारे में एक दस्तावेज़ सिंटैक्स, डिबगिंग, लाइब्रेरी और डेटा प्रकार जैसे विषयों से बना हो सकता है।
लेटेंट डिरिचलेट एलोकेशन एक अप्रशिक्षित मशीन लर्निंग एल्गोरिदम है जिसका उपयोग प्राकृतिक भाषा प्रसंस्करण में दस्तावेजों के एक बड़े संग्रह में मौजूद छिपे हुए विषयों को उजागर करने के लिए किया जाता है। यह प्रत्येक दस्तावेज़ को विषयों के एक सेट को निर्दिष्ट करके काम करता है, और फिर इस संभावना को निर्धारित करने के लिए एक जेनरेटिव संभाव्य मॉडल का उपयोग करता है कि दस्तावेज़ में एक निश्चित शब्द किसी विशेष विषय से संबंधित है।
एल्गोरिदम दो मापदंडों का उपयोग करता है - विषयों की संख्या और प्रत्येक विषय में शब्दों का वितरण। मॉडल मानता है कि विषयों का एक निश्चित सेट है (जिसे "पूर्व" कहा जाता है) जो सभी दस्तावेज़ों द्वारा साझा किया जाता है और प्रत्येक दस्तावेज़ के लिए यह उन विषयों के वितरण की खोज करता है। ई-कॉमर्स और ईमेल मार्केटिंग अनुप्रयोगों में दस्तावेजों जैसे बड़े टेक्स्ट कॉर्पोरा को मॉडल करने के लिए लेटेंट डिरिचलेट आवंटन को सफलतापूर्वक लागू किया गया है।
एलडीए का उपयोग दस्तावेजों के विषयों को निर्धारित करने और दस्तावेज़ में प्रत्येक विषय के सापेक्ष महत्व को मापने के लिए किया जा सकता है। इसका उपयोग यह पहचानने के लिए भी किया जा सकता है कि कौन से दस्तावेज़ समान विषयों पर चर्चा कर रहे हैं, या समान दस्तावेज़ों को एक साथ समूहित करने के लिए। इसके अलावा, इसका उपयोग किसी उपयोगकर्ता को उन विषयों के आधार पर अतिरिक्त सामग्री की अनुशंसा करने के लिए किया जा सकता है जिनमें उनकी पहले से ही रुचि है।
अव्यक्त डिरिचलेट आवंटन प्राकृतिक भाषा प्रसंस्करण के क्षेत्र में एक महत्वपूर्ण उपकरण है और इसका उपयोग पाठ वर्गीकरण, विषय मॉडलिंग और दस्तावेज़ क्लस्टरिंग जैसे अनुप्रयोगों में तेजी से किया जा रहा है। इसका उपयोग दस्तावेज़ों के बड़े संग्रहों का कुशलतापूर्वक विश्लेषण करने और उन दस्तावेज़ों के विषयों को समझने और व्याख्या करने के लिए किया जा सकता है।