Latent Dirichlet Allocation (LDA) je typ statistického modelu, který odhaduje témata spojená s danou sadou dokumentů na základě předpokladu, že dokumenty v sadě jsou kolekce témat z předem definované množiny. Například dokument o programovacím jazyce se může skládat z témat, jako je syntaxe, ladění, knihovny a datové typy.
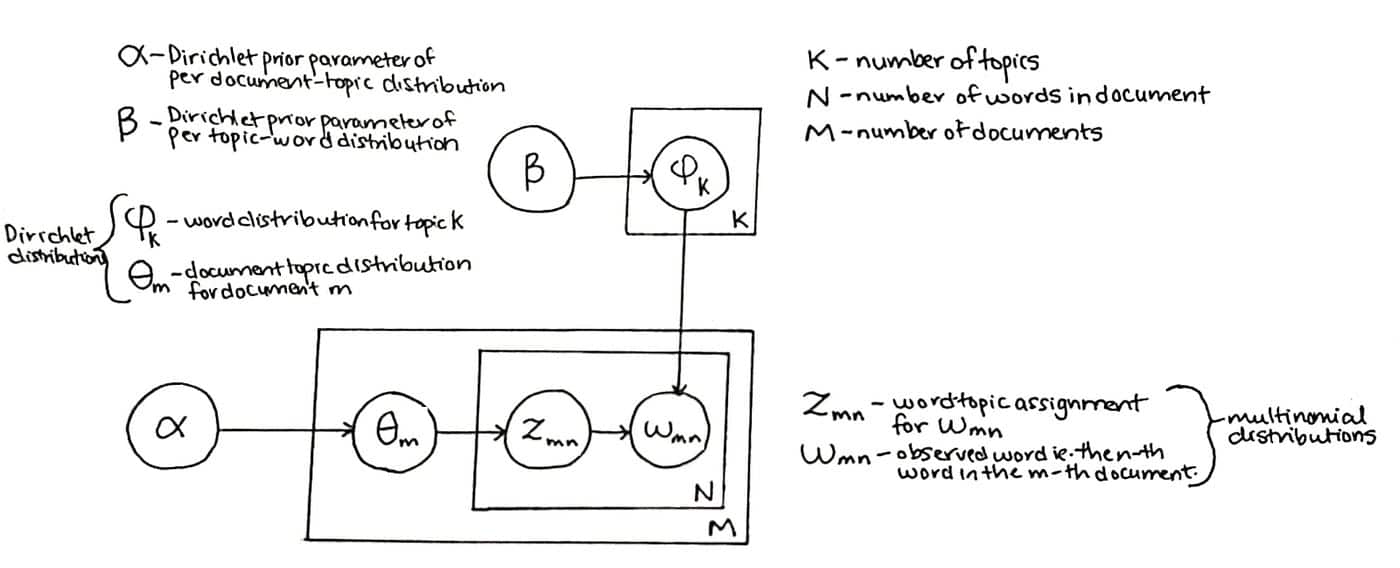
Latent Dirichlet Allocation je algoritmus strojového učení bez dozoru používaný při zpracování přirozeného jazyka k odhalování skrytých témat, která jsou přítomna ve velkém korpusu dokumentů. Funguje tak, že každý dokument se přiřadí k sadě témat a poté pomocí generativního pravděpodobnostního modelu určí pravděpodobnost, že určité slovo v dokumentu patří k určitému tématu.
Algoritmus používá dva parametry – počet témat a rozložení slov v každém tématu. Model předpokládá, že existuje pevná sada témat (nazývaná „předchozí“), která jsou sdílena všemi dokumenty, a pro každý dokument hledá distribuce těchto témat. Latentní dirichletová alokace byla úspěšně aplikována na modelování velkých textových korpusů, jako jsou dokumenty v aplikacích elektronického obchodování a e-mailového marketingu.
LDA lze použít k určení témat dokumentů a k měření relativní důležitosti každého tématu v dokumentu. Lze jej také použít k identifikaci dokumentů, které probírají stejná témata, nebo k seskupení podobných dokumentů dohromady. Kromě toho jej lze použít k doporučení dalšího obsahu uživateli na základě témat, která ho již zajímají.
Latent Dirichlet Allocation je důležitým nástrojem v oblasti zpracování přirozeného jazyka a stále více se používá v aplikacích, jako je klasifikace textu, modelování témat a shlukování dokumentů. Lze jej použít k efektivní analýze rozsáhlých sbírek dokumentů ak pochopení a interpretaci témat těchto dokumentů.