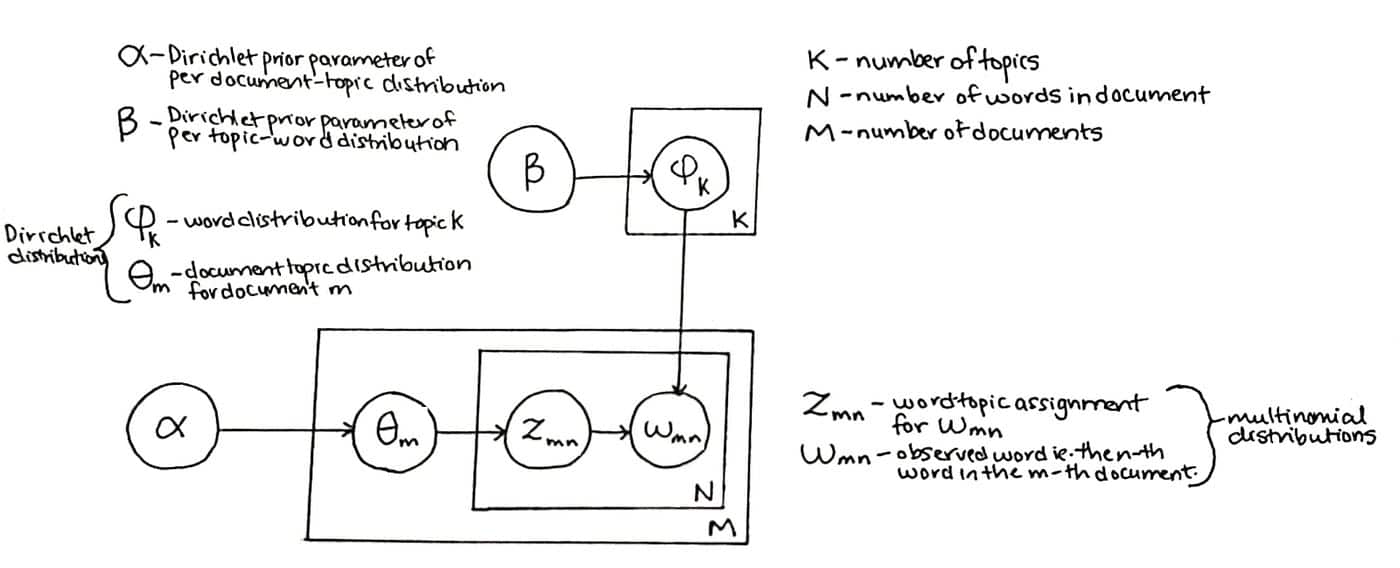
Latent Dirichlet Allocation (LDA) to rodzaj modelu statystycznego, który szacuje tematy powiązane z danym zbiorem dokumentów, w oparciu o założenie, że dokumenty w zestawie są kolekcjami tematów z predefiniowanego zestawu. Na przykład dokument dotyczący języka programowania może składać się z tematów takich jak składnia, debugowanie, biblioteki i typy danych.
Latent Dirichlet Allocation to nienadzorowany algorytm uczenia maszynowego wykorzystywany w przetwarzaniu języka naturalnego do odkrywania ukrytych tematów obecnych w dużym korpusie dokumentów. Działa poprzez przypisanie każdego dokumentu do zestawu tematów, a następnie wykorzystuje generatywny model probabilistyczny do określenia prawdopodobieństwa, że określone słowo w dokumencie należy do określonego tematu.
Algorytm wykorzystuje dwa parametry - liczbę tematów i rozkład słów w każdym temacie. Model zakłada, że istnieje stały zestaw tematów (zwany "prior"), które są wspólne dla wszystkich dokumentów i dla każdego dokumentu wyszukuje rozkłady tych tematów. Latent Dirichlet Allocation został z powodzeniem zastosowany do modelowania dużych korpusów tekstowych, takich jak dokumenty w handlu elektronicznym i aplikacjach e-mail marketingowych.
LDA może być używana do określania tematów dokumentów i mierzenia względnego znaczenia każdego tematu w dokumencie. Można go również wykorzystać do określenia, które dokumenty omawiają te same tematy lub do grupowania podobnych dokumentów. Ponadto można go wykorzystać do rekomendowania użytkownikowi dodatkowych treści w oparciu o tematy, którymi jest już zainteresowany.
Latent Dirichlet Allocation jest ważnym narzędziem w dziedzinie przetwarzania języka naturalnego i jest coraz częściej wykorzystywane w aplikacjach takich jak klasyfikacja tekstu, modelowanie tematów i grupowanie dokumentów. Może być wykorzystywana do wydajnej analizy dużych zbiorów dokumentów oraz do zrozumienia i interpretacji tematów tych dokumentów.