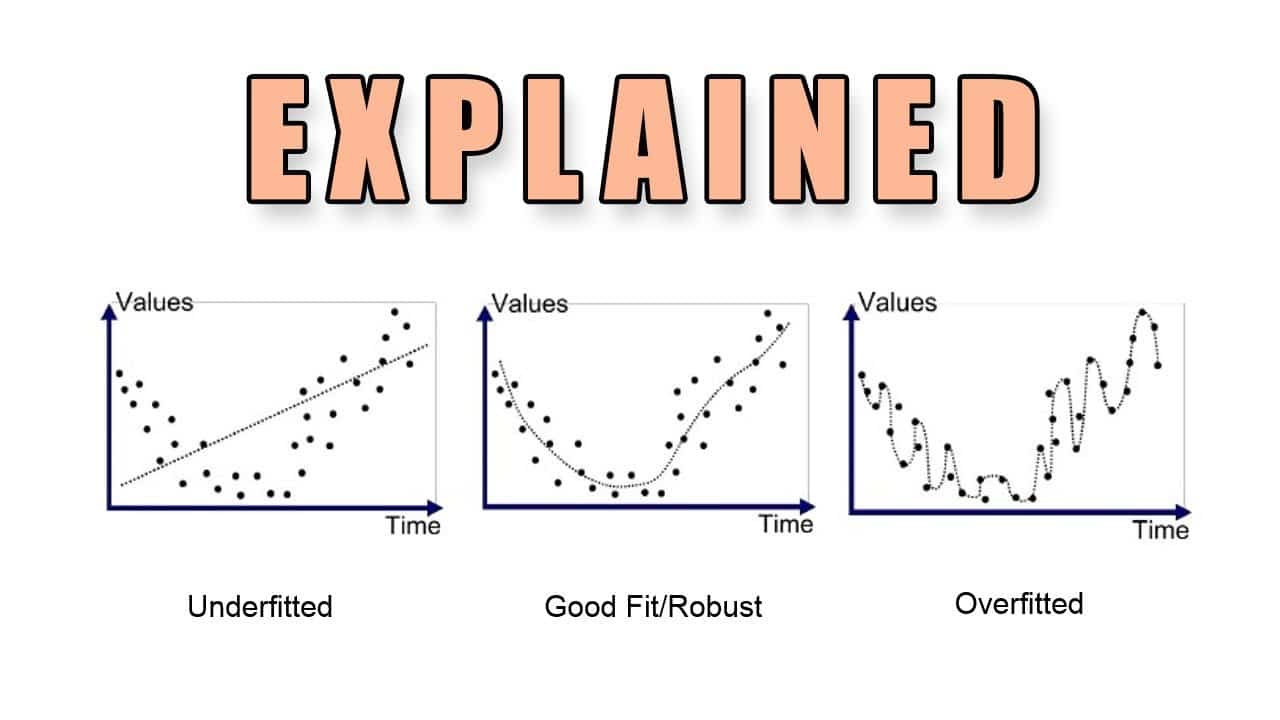
機械学習における過学習とは、機械学習モデルがトレーニング データではうまく機能するものの、新しいデータに一般化できない状況を説明するために使用される用語です。これは、モデルが複雑すぎて多くのパラメーターがあり、各パラメーターがトレーニング データセットに合わせて特別に調整されている場合に発生します。過学習は、モデルが単純すぎてデータの構造を捕捉できない場合にも発生する可能性があります。
一般に、過学習は、モデルが複雑すぎて、トレーニング データに存在する正確なパターンやノイズを学習する場合に発生します。モデルは限られたデータのサブセットでトレーニングされており、パターンから一般化するのではなくパターンを記憶する傾向があるため、サンプル外データにおけるモデルのパフォーマンスに悪影響を及ぼします。
機械学習モデルの過学習は通常、複数の要因の組み合わせによって発生します。これには、データの不足、データが多すぎる、ターゲットの動作を説明するのに必要以上に複雑なモデル、または冗長な情報を持つ説明変数が多すぎるなどが含まれます。
過学習を回避するには、トレーニング データを適切に選択し、適切なモデルを構築する必要があります。一般化の精度を向上させるために一般的に使用される手法には、縮小、サブセット選択、倹約ベースの手法などの正則化手法が含まれます。同様に、モデルが過剰適合していないかどうかを確認するために、推定後のチェックも実行する必要があります。最後に、強力なデータ視覚化手法を使用してデータとモデルの構造を解明することによって、過剰適合の可能性を減らすこともできます。