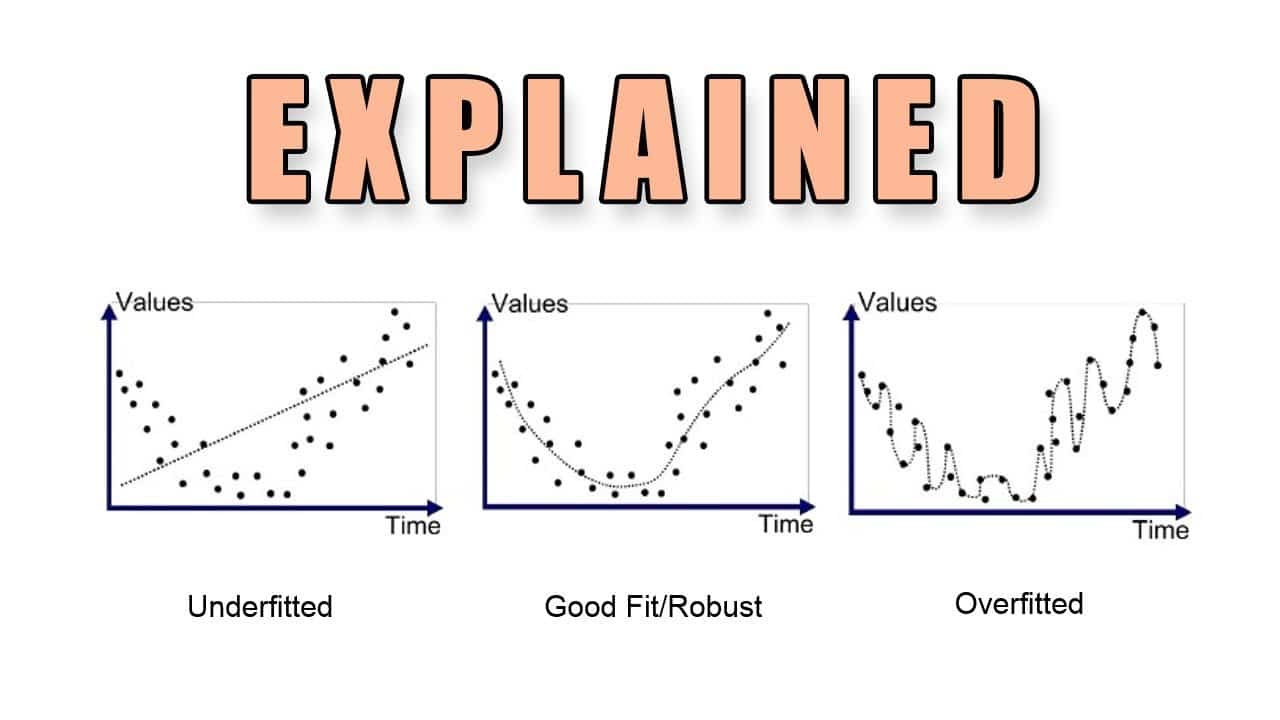
L'overfitting nell'apprendimento automatico è un termine usato per descrivere una situazione in cui un modello di apprendimento automatico ottiene buone prestazioni sui dati di addestramento, ma non riesce a generalizzare a nuovi dati. Si verifica quando il modello è troppo complesso e ha molti parametri, ognuno dei quali è specificamente tarato sul set di dati di addestramento. L'overfitting può verificarsi anche quando il modello è troppo semplice e non riesce a catturare la struttura dei dati.
In generale, l'overfitting si verifica quando un modello è troppo complesso e apprende esattamente i modelli o il rumore presenti nei dati di addestramento. Ha un effetto negativo sulle prestazioni del modello nei dati fuori campione, poiché è stato addestrato su un sottoinsieme limitato di dati e tende a memorizzare i modelli piuttosto che generalizzarli.
L'overfitting nei modelli di apprendimento automatico deriva tipicamente da una combinazione di fattori. Tra questi, la mancanza o l'eccesso di dati, una complessità del modello superiore a quella necessaria per spiegare il comportamento desiderato o un numero eccessivo di variabili esplicative con informazioni ridondanti.
Per evitare l'overfitting, è necessario selezionare correttamente i dati di addestramento e costruire un modello adeguato. Le tecniche comunemente utilizzate per migliorare l'accuratezza della generalizzazione includono metodi di regolarizzazione come lo shrinkage, la selezione dei sottoinsiemi e le tecniche basate sulla parsimonia. Inoltre, è necessario effettuare controlli successivi alla stima per assicurarsi che il modello non sia in overfitting. Infine, l'uso di potenti tecniche di visualizzazione dei dati per aiutare a chiarire la struttura dei dati e del modello può ridurre le possibilità di overfitting.