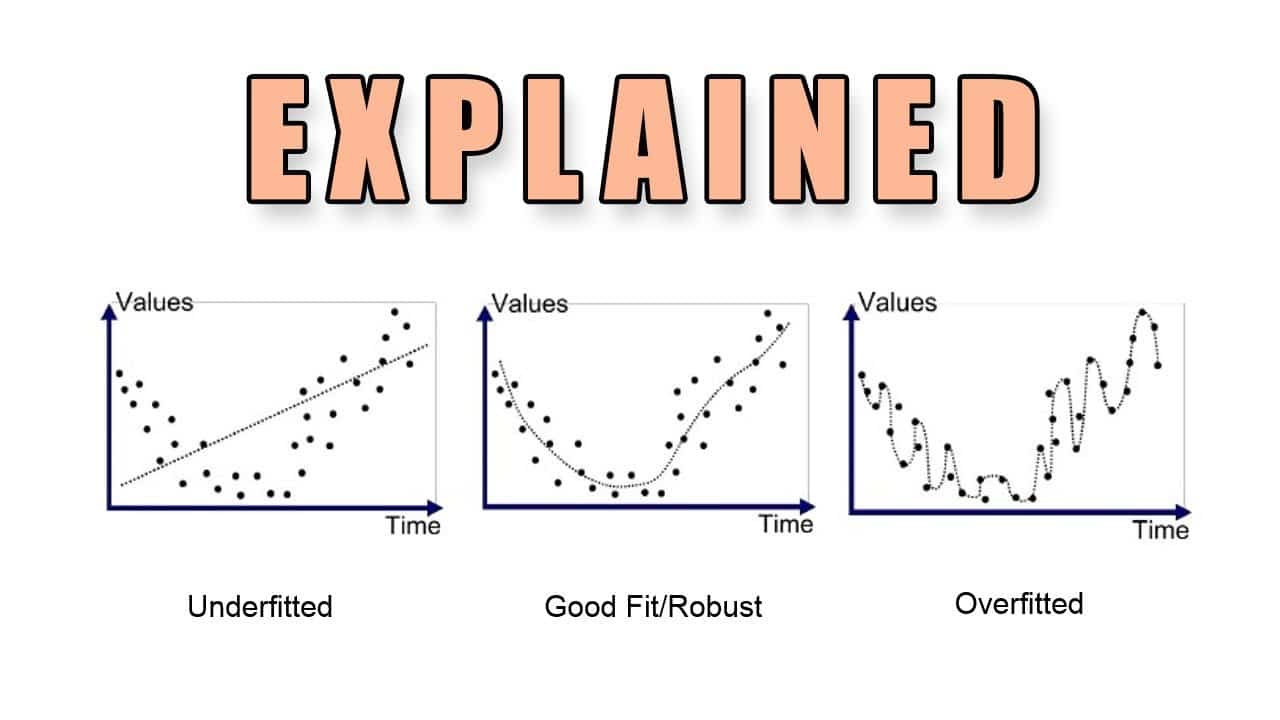
Overfitting no aprendizado de máquina é um termo usado para descrever uma situação em que um modelo de aprendizado de máquina tem bom desempenho em dados de treinamento, mas não consegue generalizar para novos dados. Isso ocorre quando o modelo é muito complexo e tem muitos parâmetros, cada um deles ajustado especificamente ao conjunto de dados de treinamento. O sobreajuste também pode ocorrer quando o modelo é muito simples e não consegue capturar a estrutura dos dados.
Em geral, o ajuste excessivo ocorre quando um modelo é muito complexo e aprende os padrões exatos ou o ruído presente nos dados de treinamento. Isso tem um efeito negativo sobre o desempenho do modelo em dados fora da amostra, pois ele foi treinado em um subconjunto limitado de dados e tende a memorizar os padrões em vez de generalizá-los.
O excesso de ajuste nos modelos de aprendizado de máquina geralmente decorre de uma combinação de fatores. Entre eles estão a falta ou o excesso de dados, a complexidade do modelo maior do que o necessário para explicar o comportamento-alvo ou o excesso de variáveis explicativas com informações redundantes.
Para evitar o ajuste excessivo, os dados de treinamento devem ser selecionados corretamente e um modelo adequado deve ser construído. As técnicas comumente usadas para melhorar a precisão da generalização incluem métodos de regularização como encolhimento, seleção de subconjuntos e técnicas baseadas em parcimônia. Além disso, verificações pós-estimação também devem ser realizadas para garantir que o modelo não esteja se ajustando demais. Por fim, o uso de técnicas avançadas de visualização de dados para ajudar a elucidar a estrutura dos dados e do modelo também pode reduzir as chances de ajuste excessivo.