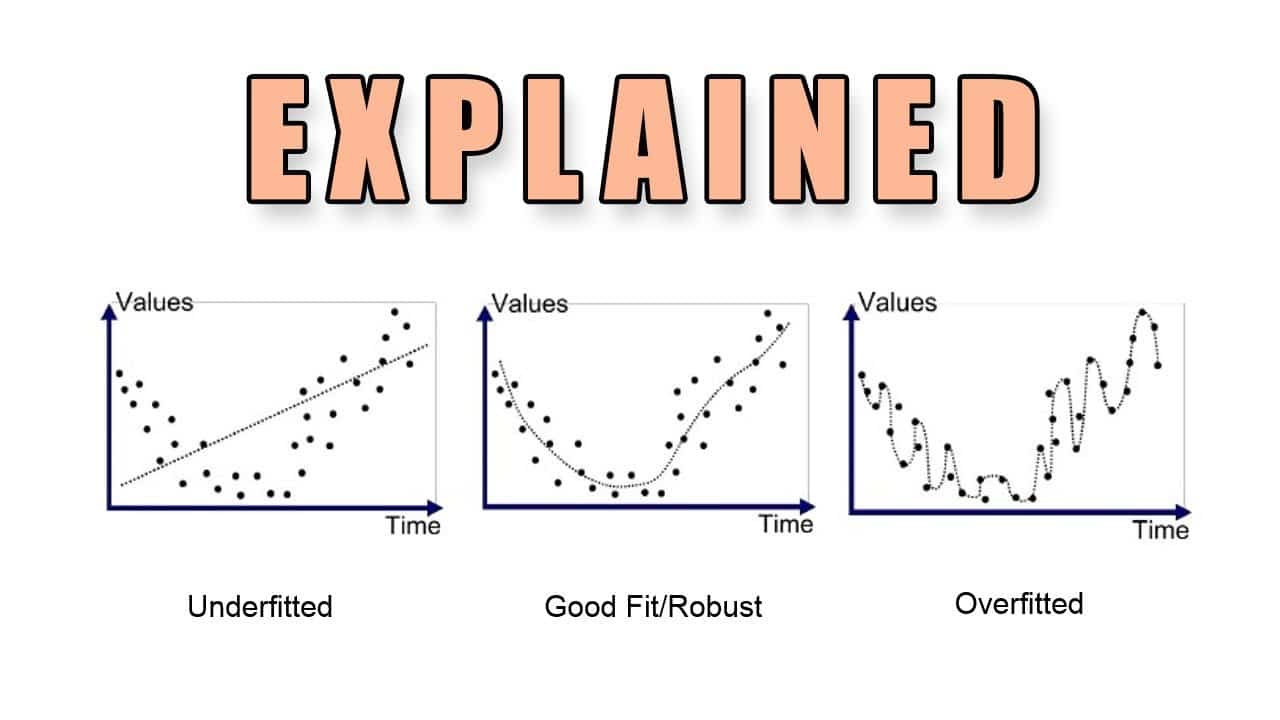
Overfitting in Machine Learning is a term used to describe a situation where a machine learning model performs well on training data but fails to generalize to new data. It occurs when the model is too complex and has many parameters, each of which are specifically tuned to the training dataset. Overfitting can also occur when the model is too simple and fails to capture the structure of the data.
In general, overfitting occurs when a model is too complex and learns the exact patterns or noise present in the training data. It has a negative effect on the model’s performance in out-of-sample data, since it has been trained on a limited subset of data and tends to memorize the patterns rather than generalizing from them.
Overfitting in Machine Learning models typically arises from a combination of factors. These include a lack of data, or too much data, a complexity of the model that is higher than necessary to explain the target behavior, or too many explanatory variables with redundant information.
To avoid overfitting, training data must be selected properly and a suitable model must be constructed. Commonly used techniques for improving generalization accuracy include regularization methods like shrinkage, subset selection, and parsimony-based techniques. As well, post-estimation checks should also be conducted to ensure that the model is not overfitting. Finally, using powerful data visualizations techniques to help elucidate the structure of the data and model can also reduce the chances of overfitting.