Optimalisasi kebijakan proksimal (PPO) adalah rangkaian algoritma pembelajaran penguatan gradien kebijakan yang digunakan dalam kecerdasan buatan. Itu ditemukan pada tahun 2017 oleh John Schulman, Filip Wolski, Prafulla Dhariwal, AlecRadford, dan Oleg Klimov. PPO merupakan perkiraan gradien kebijakan alami yang menyederhanakan dan mempercepat prosedur pelatihan.
Algoritme PPO bekerja dengan menerapkan gradien kebijakan stokastik untuk memperbarui kebijakan agen ke arah yang meningkatkan imbalan yang diharapkan dan menstabilkan pelatihan. Hal ini dilakukan dengan menggunakan teknik optimasi yang disebut optimasi kebijakan proksimal yang memungkinkan agen menyesuaikan parameter fungsi nilai tindakannya dengan hanya mempertimbangkan fungsi nilai tindakan dalam wilayah kecil dari yang terbaik saat ini. Hal ini memastikan bahwa hanya perubahan kecil yang dilakukan dalam setiap langkah pelatihan tertentu, sehingga memungkinkan pembelajaran lebih mudah dan stabil.
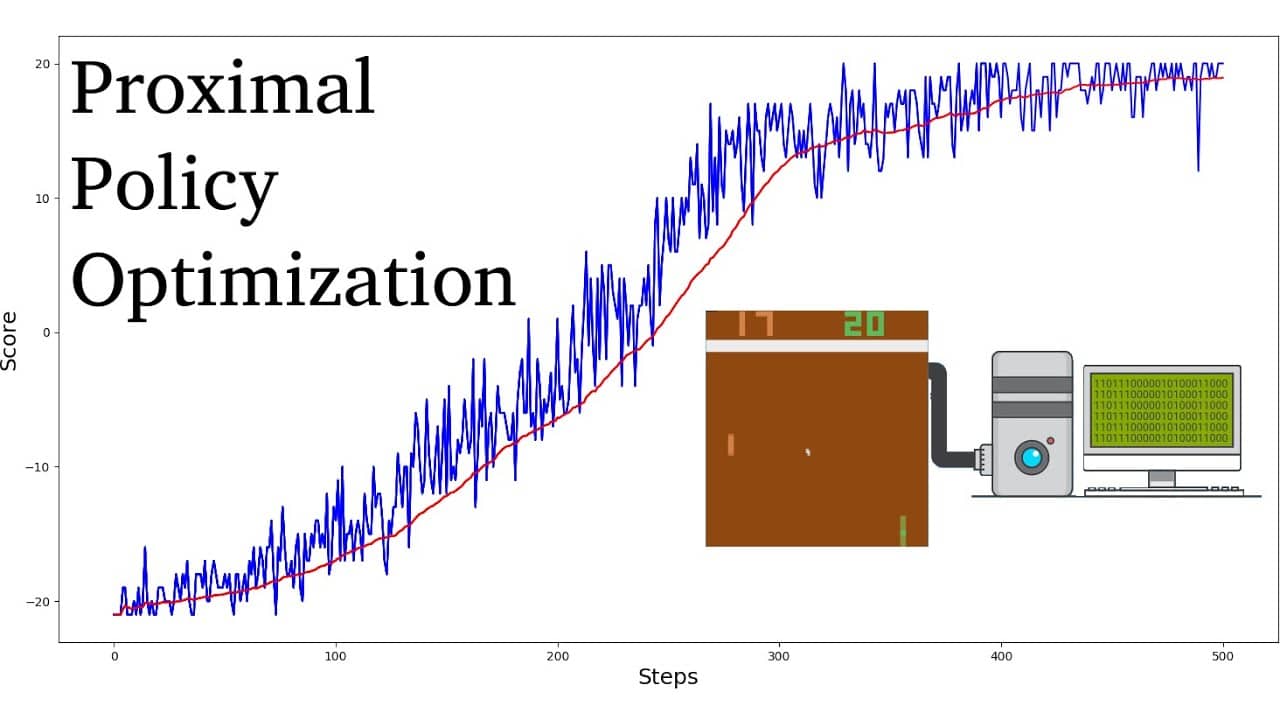
Dibandingkan dengan algoritme pembelajaran penguatan lainnya, PPO terbukti memerlukan lebih sedikit sampel dan iterasi untuk mencapai konvergensi, sekaligus mencapai nilai imbalan optimal yang lebih tinggi. Selain itu, penyetelan hyperparameter yang diperlukan untuk algoritme PPO jauh lebih sederhana dibandingkan dengan algoritme pembelajaran penguatan lainnya.
Algoritme PPO umumnya dianggap lebih efisien dalam pengambilan sampel dibandingkan algoritma gradien kebijakan lainnya seperti Trust Region Policy Optimization (TRPO). Mereka juga dikenal lebih stabil, sehingga cocok untuk aplikasi dunia nyata. Oleh karena itu, algoritme PPO telah meraih kesuksesan besar dalam bidang robotika, permainan video game, dan mengemudi otonom.