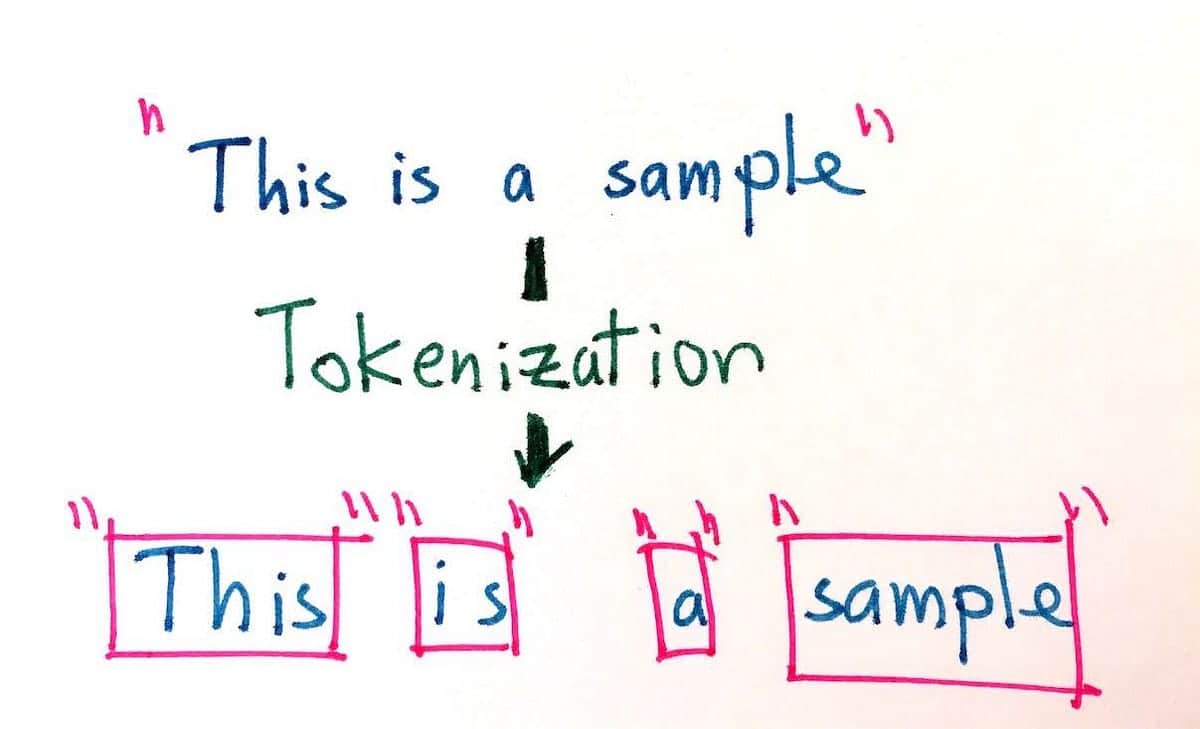
Tokenization in natural language processing is a process used to divide a given piece of text into smaller individual units that can be used to parse and evaluate the text. It is an important task in natural language processing (NLP) that aims to break down a given text into its fundamental parts, such as words, phrases, and symbols, in order to analyze its meaning. Tokenization is also used in machine translation and text-to-speech systems.
The tokenization process involves separating text into different tokens, or pieces of text, such as words, numbers, and punctuation marks. The tokens then serve as the basis for further processing, such as part-of-speech tagging, named entity recognition, and sentiment analysis. Tokenization also simplifies the process of searching for and retrieving information from text documents or databases.
The goal of tokenization is to break down long pieces of text into its smallest units to enable more precise analysis. Tokenization may be accomplished in a variety of ways, such as dividing by word boundaries, sentences, paragraphs, numbers, and characters. For example, the sentence “The dog ran quickly” could be tokenized into the following tokens: “The, dog, ran, quickly”. In addition, given the same sentence, tokenization may also accommodate different types of encoding, such as byte, Unicode, and ASCII.
The use of tokenization has become increasingly important in recent years due to the explosive growth of digital content. Tokenization makes it easier to search and use large amounts of natural language data, and it is essential for the development and improvement of artificial intelligence, particularly in the field of natural language processing. Many search engines and applications use tokenization to improve the accuracy of the results they generate. Additionally, tokenization is a key component of many speech recognition systems, in which it is used to break up spoken input into units that can be more easily identified and categorized.
By aiding in the understanding of written and spoken language, tokenization can be used to reduce the complexity of natural language databases, making it easier for users to extract relevant information and create a better user experience. As such, tokenization is an invaluable tool for both natural language processing and modern search engine applications.