La tokenización en el procesamiento del lenguaje natural es un proceso utilizado para dividir un texto dado en unidades individuales más pequeñas que pueden utilizarse para analizar y evaluar el texto. Es una tarea importante en el procesamiento del lenguaje natural (PLN) que tiene como objetivo dividir un texto en sus partes fundamentales, como palabras, frases y símbolos, para analizar su significado. La tokenización también se utiliza en la traducción automática y en los sistemas de conversión de texto en voz.
El proceso de tokenización consiste en separar el texto en diferentes tokens, o fragmentos de texto, como palabras, números y signos de puntuación. Los tokens sirven de base para el procesamiento posterior, como el etiquetado de parte del habla, el reconocimiento de entidades con nombre y el análisis de sentimientos. La tokenización también simplifica el proceso de búsqueda y recuperación de información en documentos de texto o bases de datos.
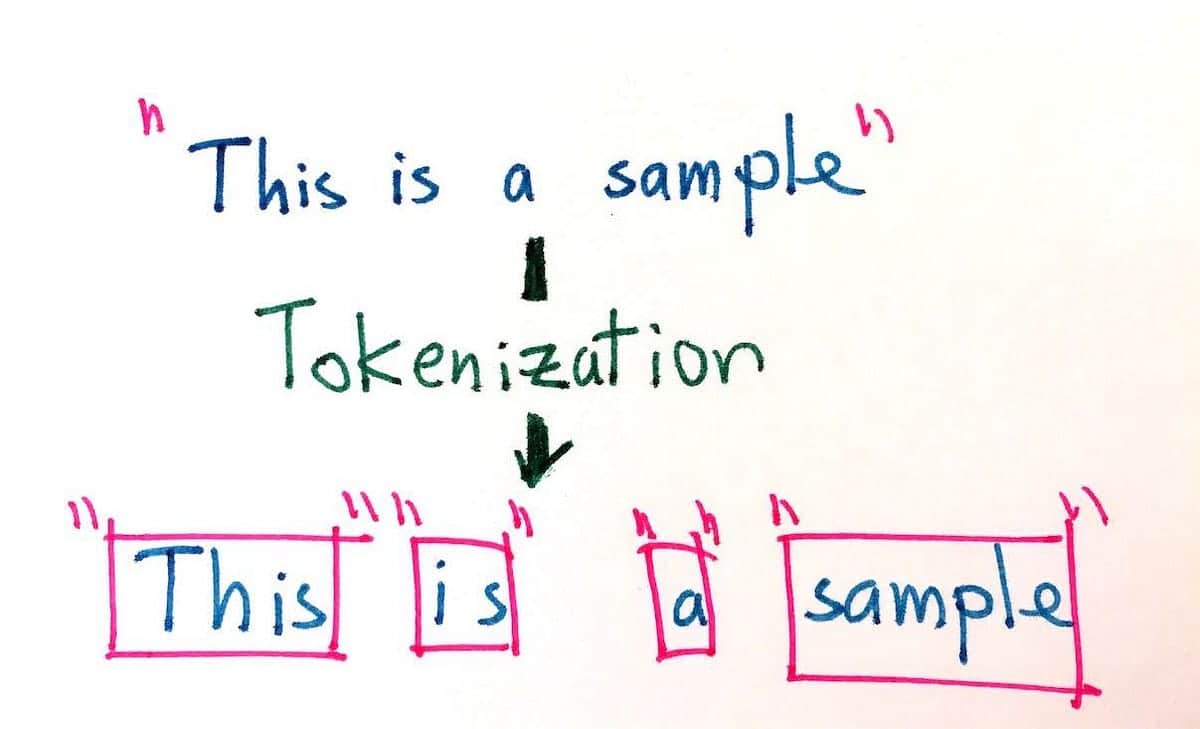
El objetivo de la tokenización es dividir los fragmentos largos de texto en sus unidades más pequeñas para permitir un análisis más preciso. La tokenización puede llevarse a cabo de varias formas, como la división por límites de palabras, frases, párrafos, números y caracteres. Por ejemplo, la frase "El perro corrió rápidamente" podría dividirse en los siguientes tokens: "El, perro, corrió, rápidamente". Además, dada la misma frase, la tokenización también puede adaptarse a distintos tipos de codificación, como byte, Unicode y ASCII.
El uso de la tokenización ha cobrado cada vez más importancia en los últimos años debido al crecimiento explosivo de los contenidos digitales. La tokenización facilita la búsqueda y el uso de grandes cantidades de datos en lenguaje natural, y es esencial para el desarrollo y la mejora de la inteligencia artificial, sobre todo en el campo del procesamiento del lenguaje natural. Muchos motores de búsqueda y aplicaciones utilizan la tokenización para mejorar la precisión de los resultados que generan. Además, la tokenización es un componente clave de muchos sistemas de reconocimiento de voz, en los que se utiliza para dividir la entrada hablada en unidades que puedan identificarse y categorizarse más fácilmente.
Al ayudar a comprender el lenguaje escrito y hablado, la tokenización puede utilizarse para reducir la complejidad de las bases de datos de lenguaje natural, facilitando a los usuarios la extracción de información relevante y creando una mejor experiencia de usuario. Por ello, la tokenización es una herramienta inestimable tanto para el procesamiento del lenguaje natural como para las aplicaciones de los motores de búsqueda modernos.