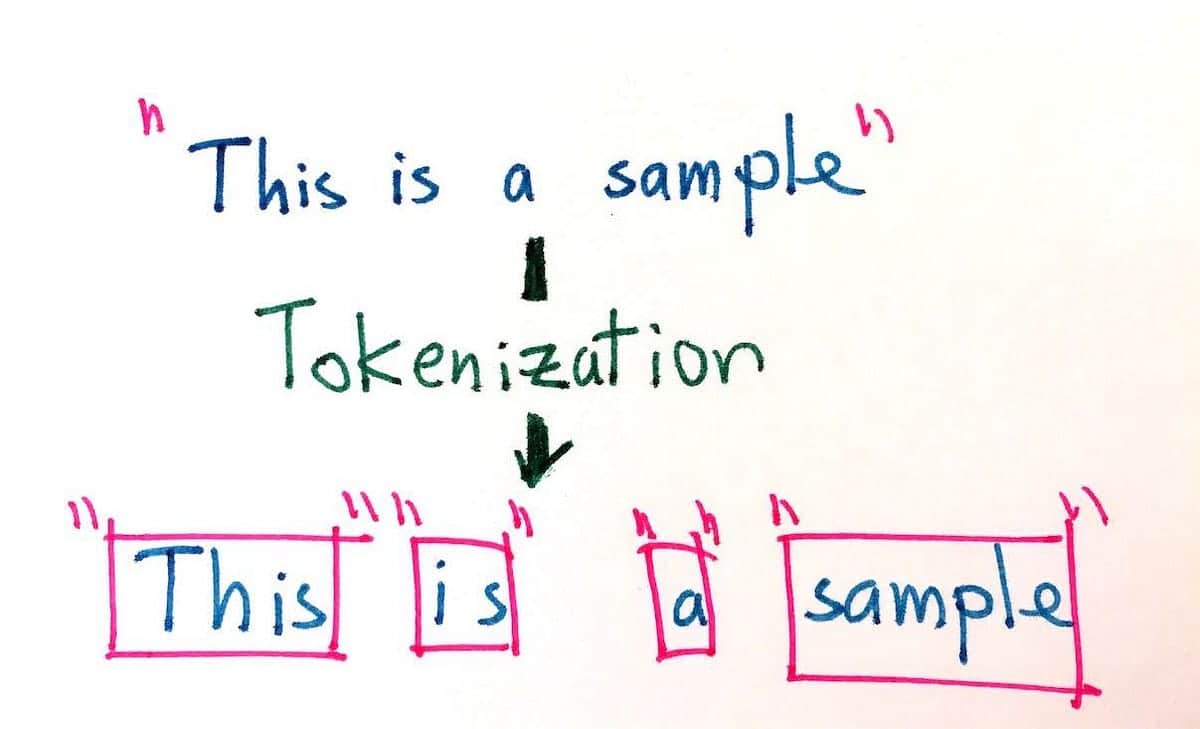
La tokenisation dans le traitement du langage naturel est un processus utilisé pour diviser un texte donné en unités individuelles plus petites qui peuvent être utilisées pour analyser et évaluer le texte. Il s'agit d'une tâche importante dans le traitement du langage naturel (NLP) qui vise à décomposer un texte donné en ses parties fondamentales, telles que les mots, les phrases et les symboles, afin d'en analyser le sens. La tokenisation est également utilisée dans les systèmes de traduction automatique et de synthèse vocale.
Le processus de tokenisation consiste à séparer le texte en différents tokens, ou morceaux de texte, tels que les mots, les chiffres et les signes de ponctuation. Les tokens servent ensuite de base à d'autres traitements, tels que l'étiquetage de la partie du discours, la reconnaissance des entités nommées et l'analyse des sentiments. La tokenisation simplifie également le processus de recherche et d'extraction d'informations dans les documents textuels ou les bases de données.
L'objectif de la tokenisation est de diviser de longs morceaux de texte en unités plus petites afin de permettre une analyse plus précise. La tokenisation peut être réalisée de différentes manières, notamment en divisant le texte par des mots, des phrases, des paragraphes, des nombres et des caractères. Par exemple, la phrase "Le chien a couru rapidement" peut être transformée en jetons : "Le, chien, a couru, rapidement". En outre, pour une même phrase, la tokenisation peut également prendre en compte différents types d'encodage, tels que byte, Unicode et ASCII.
L'utilisation de la tokenisation est devenue de plus en plus importante ces dernières années en raison de la croissance explosive du contenu numérique. La tokenisation facilite la recherche et l'utilisation de grandes quantités de données en langage naturel, et elle est essentielle au développement et à l'amélioration de l'intelligence artificielle, en particulier dans le domaine du traitement du langage naturel. De nombreux moteurs de recherche et applications utilisent la tokenisation pour améliorer la précision des résultats qu'ils génèrent. En outre, la tokenisation est un élément clé de nombreux systèmes de reconnaissance vocale, dans lesquels elle est utilisée pour diviser les données vocales en unités qui peuvent être plus facilement identifiées et catégorisées.
En facilitant la compréhension du langage écrit et parlé, la tokenisation peut être utilisée pour réduire la complexité des bases de données en langage naturel, ce qui permet aux utilisateurs d'extraire plus facilement des informations pertinentes et de créer une meilleure expérience utilisateur. En tant que telle, la tokenisation est un outil inestimable pour le traitement du langage naturel et les applications des moteurs de recherche modernes.