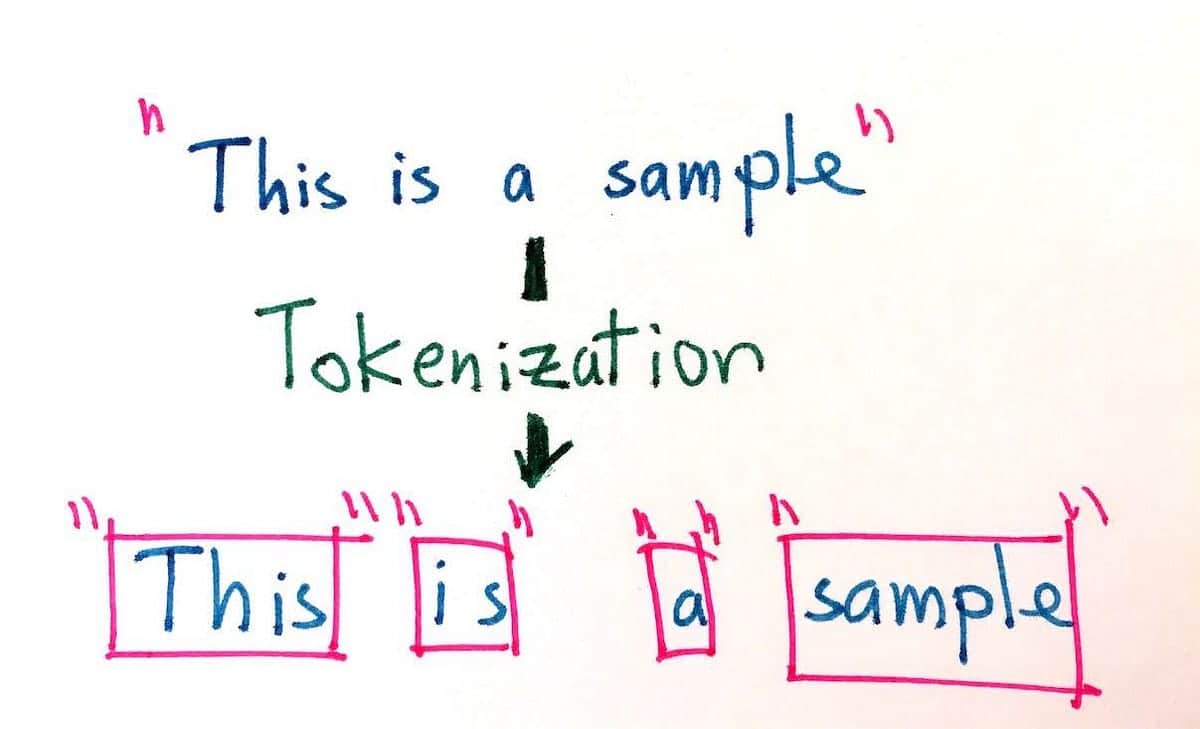
A tokenização no processamento de linguagem natural é um processo usado para dividir uma determinada parte do texto em unidades individuais menores que podem ser usadas para analisar e avaliar o texto. É uma tarefa importante no processamento de linguagem natural (NLP) que tem como objetivo dividir um determinado texto em suas partes fundamentais, como palavras, frases e símbolos, para analisar seu significado. A tokenização também é usada em sistemas de tradução automática e de conversão de texto em fala.
O processo de tokenização envolve a separação do texto em diferentes tokens, ou partes do texto, como palavras, números e sinais de pontuação. Os tokens servem como base para o processamento posterior, como marcação de parte da fala, reconhecimento de entidades nomeadas e análise de sentimentos. A tokenização também simplifica o processo de busca e recuperação de informações de documentos de texto ou bancos de dados.
O objetivo da tokenização é dividir longos trechos de texto em suas menores unidades para permitir uma análise mais precisa. A tokenização pode ser realizada de várias maneiras, como a divisão por limites de palavras, frases, parágrafos, números e caracteres. Por exemplo, a frase "The dog ran quickly" (O cachorro correu rapidamente) poderia ser tokenizada nos seguintes tokens: "The, dog, ran, quickly". Além disso, considerando a mesma frase, a tokenização também pode acomodar diferentes tipos de codificação, como byte, Unicode e ASCII.
O uso da tokenização tem se tornado cada vez mais importante nos últimos anos devido ao crescimento explosivo do conteúdo digital. A tokenização facilita a pesquisa e o uso de grandes quantidades de dados de linguagem natural e é essencial para o desenvolvimento e o aprimoramento da inteligência artificial, especialmente no campo do processamento de linguagem natural. Muitos mecanismos e aplicativos de pesquisa usam a tokenização para melhorar a precisão dos resultados que geram. Além disso, a tokenização é um componente essencial de muitos sistemas de reconhecimento de fala, no qual é usada para dividir a entrada falada em unidades que podem ser mais facilmente identificadas e categorizadas.
Ao auxiliar na compreensão da linguagem escrita e falada, a tokenização pode ser usada para reduzir a complexidade dos bancos de dados de linguagem natural, facilitando a extração de informações relevantes e criando uma melhor experiência para o usuário. Dessa forma, a tokenização é uma ferramenta inestimável para o processamento de linguagem natural e para os aplicativos modernos de mecanismos de pesquisa.