Apache Pig는 데이터 분석을 더 빠르고 쉽게 수행할 수 있도록 설계된 오픈 소스 데이터 처리 플랫폼입니다. Hadoop 플랫폼을 기반으로 구축되었으며 주로 조직에서 데이터 분석 및 기계 학습 작업을 위해 대규모 데이터 세트에서 데이터를 추출하는 데 사용됩니다. 2007년 Yahoo가 개발한 Pig는 인기 있는 스크립팅 및 쿼리 언어인 Pig Latin으로 작성되었으며, 이를 통해 사용자는 SQL과 유사한 명령을 사용하여 프로그램을 작성할 수 있습니다.
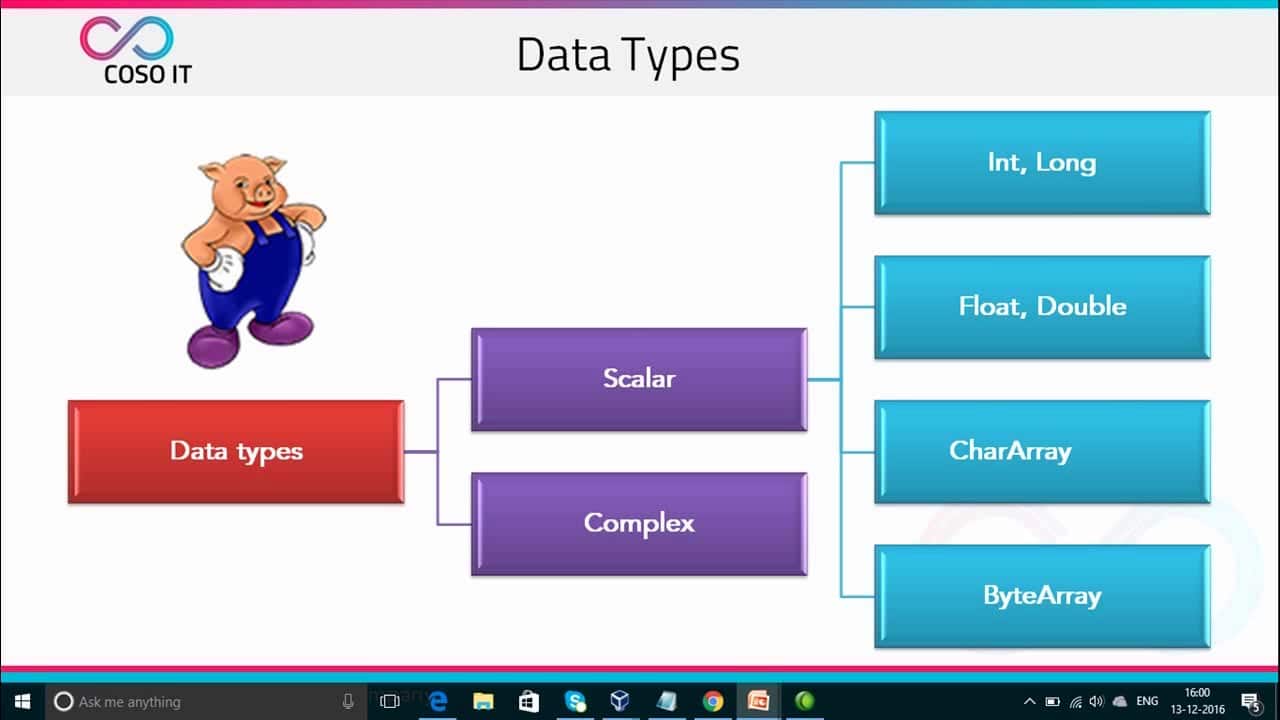
가장 간단한 형태로 Pig는 대규모 데이터 세트에서 데이터 필터링, 집계 및 정렬 작업을 수행하는 데 사용할 수 있습니다. 예를 들어 Apache Pig에 대한 쿼리를 사용하면 서로 다른 두 소스의 데이터를 결합하고, 간단한 통계를 계산하고, 그룹화 및 계산과 같은 작업을 수행할 수 있습니다. Pig Latin의 구문은 SQL과 유사하지만 훨씬 더 표현력이 뛰어나고 복잡한 데이터 유형, 사용자 정의 함수, 사용자 정의 데이터 로딩과 같은 작업을 포함합니다.
Hadoop의 MapReduce에 비해 Pig Latin의 주요 장점은 복잡한 함수를 작성하는 것이 더 강력하고 간단하다는 것입니다. 이로 인해 빅 데이터 프로젝트를 수행하는 데이터 분석가 및 개발자에게 인기가 있습니다. 또한 더욱 직관적이며 개발 주기가 더욱 빨라졌습니다. Pig는 Hive, Sqoop, HCatalog, Spark 및 Oozie와 같은 다른 Apache 프로젝트와 함께 사용할 수도 있습니다.
데이터 처리에 사용되는 것 외에도 Apache Pig는 다양한 유형의 데이터 시각화 및 데이터 과학 프로젝트에도 사용할 수 있습니다. Apache Spark 및 Hadoop과 같은 다른 오픈 소스 프로젝트와 함께 시각적 대시보드 및 기타 형태의 데이터 분석을 만드는 데 자주 사용됩니다.
간단히 말해서, Apache Pig는 대규모 데이터 세트 분석 프로세스를 단순화하여 사용자가 데이터에서 정보를 신속하게 추출하고 처리할 수 있게 해주는 오픈 소스 데이터 처리 플랫폼입니다. 사용 편의성, 강력한 기능, 광범위한 사용 사례를 갖춘 이 제품은 데이터 분석가와 개발자 사이에서 인기 있는 선택입니다.