Apache Pig è una piattaforma di elaborazione dati open source progettata per rendere il processo di esecuzione dell'analisi dei dati più semplice e veloce. È costruito sulla piattaforma Hadoop ed è utilizzato principalmente dalle organizzazioni per estrarre dati da set di dati di grandi dimensioni per le loro attività di analisi dei dati e di apprendimento automatico. Sviluppato da Yahoo nel 2007, Pig è scritto nel popolare linguaggio di scripting e di query Pig Latin, che consente agli utenti di scrivere programmi utilizzando comandi simili a SQL.
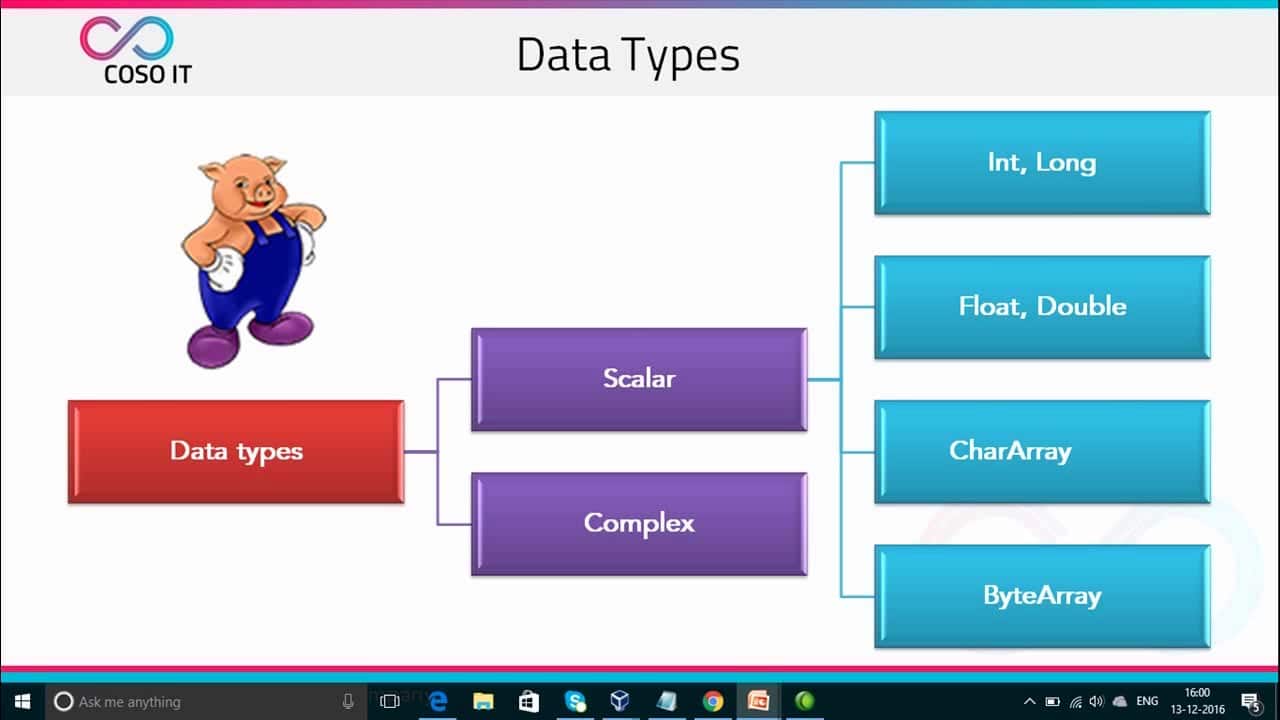
Nella sua forma più semplice, Pig può essere utilizzato per eseguire operazioni di filtraggio, aggregazione e ordinamento dei dati su set di dati di grandi dimensioni. Ad esempio, una query su Apache Pig può essere utilizzata per unire dati provenienti da due origini diverse, calcolare semplici statistiche ed eseguire operazioni come raggruppamento e conteggio. Sebbene la sintassi di Pig Latin sia simile a SQL, è molto più espressiva e include operazioni come tipi di dati complessi, funzioni definite dall'utente e caricamento di dati personalizzati.
Il vantaggio principale di Pig Latin rispetto a MapReduce di Hadoop è che è più potente e più semplice scrivere funzioni complesse. Ciò lo rende popolare tra gli analisti di dati e gli sviluppatori che lavorano con progetti Big Data. È anche più intuitivo e consente cicli di sviluppo più rapidi. Pig può essere utilizzato anche insieme ad altri progetti Apache come Hive, Sqoop, HCatalog, Spark e Oozie.
Oltre all'utilizzo nell'elaborazione dei dati, Apache Pig può essere utilizzato anche in vari tipi di visualizzazione dei dati e progetti di Data Science. Viene spesso utilizzato insieme ad altri progetti open source come Apache Spark e Hadoop per creare dashboard visivi e altre forme di analisi dei dati.
In breve, Apache Pig è una piattaforma di elaborazione dati open source che semplifica il processo di analisi di set di dati di grandi dimensioni, consentendo agli utenti di estrarre ed elaborare rapidamente le informazioni dai propri dati. Grazie alla sua facilità d'uso, alle sue potenti funzionalità e all'ampia gamma di casi d'uso, è una scelta popolare tra gli analisti di dati e gli sviluppatori.